
As Editor-in-Chief of a major AGU journal I frequently deal with inquiries from authors about the process of having their papers accepted for publication. Nothing in the recent past has generated more correspondence than the matter of data reporting requirements, particularly the fact that we no longer permit the statement of “Data available by contacting the author.” I would like to describe, using some personal examples, why AGU’s new data policy is both necessary and a benefit to all.
Why the numbers are important
When you publish a research paper, you are also simultaneously publishing the data that supports your work. The readers of your article have equal rights to see both the words and the numbers – they are inseparable.
But what constitutes “data”? What about the raw instrument readings? What about the calibration runs? What about all the model code? etc, etc. Those data may well be deposited on local institutional servers and serve as backup for the team. Many fields have developed standards of practice for what is generally reported and stored as a single result from a run or measurement; these in some cases include the raw readings, in others a derived measurement and information on how it was obtained or processed from the raw data, or both. These standards are often set through repositories. Thus, for publication in JGR: Oceans and all the other AGU journals, at least these data need to be available in a publicly accessible repository.
We need the numbers – all the numbers – behind the published figures, graphs, contour plots etc.
We need the numbers – all the numbers – behind the published figures, graphs, contour plots etc. And these need to be specific; that is not averages within regions and so on. Your readers may well wish to re-plot these data to test a pet theory, or to assign them as a class problem, or to combine the results in a major review article. That is what your work is for.
How it came about
In May 2013, there was an Executive Order signed by President Obama and an Open Data Policy that applied to all US Federal Departments and Agencies, which declared that all data generated by the government be made open and accessible to the public.
Implementation of this policy in the context of the Earth Sciences was carefully reviewed at a workshop in May 2015 convened by then Editor-in-Chief of Science, Marcia McNutt. In fact, the US system was playing “catch up” as the routine deposition of data essential to support scientific publication has been far more common in Europe, where the PANGAEA data repository for Earth and environmental science is well established.
Representatives of all the major associations and publishing companies in the Earth Sciences were there, as was a senior NSF representative. Brooks Hanson, Senior Vice President for Publications, and I represented AGU. The outcome of this workshop was published in Science [McNutt et al., 2016].
Partly as a result, AGU revised and updated their data policy, and its implementation, adopting new data acknowledgement requirements for publication in all AGU journals.
“Data available by contacting the corresponding author” is no longer acceptable for our journals
Basically, the commonly-used statement “Data available by contacting the corresponding author” is no longer acceptable for our journals. Data must be stored in a domain repository that is accessible to all, and this information must be explicitly stated in the Acknowledgements section of the paper. Further information is here.
Problems and perils of the old system
I would like to share two examples from my personal experience of why the old system just doesn’t work.
In September 2016 colleagues and I organized a UK Royal Society Discussion Meeting on Ocean Ventilation and Deoxygenation in a Warming World. My own contribution to this meeting was to provide a synthesis of tracer and model-based estimates of deep ocean oxygen consumption rates, almost all of which have been published in AGU journals and for some of these contributions I personally served as Editor.
In order to do this, I wrote to the authors of the papers asking for copies of the data files accompanying their published work. Not once did I receive a “Sure, I am happy to do that” reply: delay, obfuscation, pleas of being busy, and so on was the rule. In many cases these were colleagues I knew well. These are not big data files and typical profiles are only of a dozen or so depths. These are simple requests, but help was not at hand. Eventually I was able to put together a compilation and the work has now been published [Brewer and Peltzer, 2017]. But the ugly truth is that in some cases I was reduced to blowing up figures on the copier and drawing pencil lines across the image!
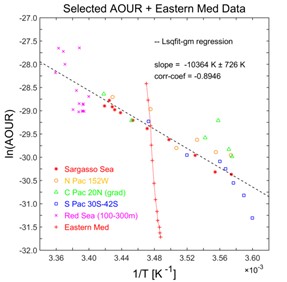
Far more problematic is the matter of job mobility or human frailty. In Figure 6 that we plotted for Brewer and Peltzer [2017] (see right), one ocean profile ran almost exactly orthogonal to all the others. It was a hugely anomalous result and no reasonable explanation could be found.
The problem was definitely not measurement quality as the lab and the principal investigator had been known for superior work for decades.
However, the results we used did not come from a published data table as that was not given in the original paper; instead they were taken from a simple published equation written as a function of depth that reportedly represented the observations well.
It appeared to us that a misprint might have occurred and we contacted the corresponding author.
Alas, too much time had gone by since the paper was published in 2001 and our colleague was now suffering from badly failing eye sight, the student who executed the work and provided the data equation had moved on and contact had been lost. The original data are now not discoverable and we have no way of resolving this puzzle.
Your data are valuable and need to be shared
These are not isolated examples. My experience has been sobering. We need to do better than this. Your data are valuable and need to be shared – this will bring you nothing but credit and honor.
A positive example of the new system
I have had more than a few irate messages along the lines of “Do you expect me to just give my data away so that anyone can use it?” The answer is “yes”. For such skeptics, let me share an active example of large scale data archiving and sharing in the ocean sciences that works well.
The Gulf of Mexico Research Initiative established after the tragic April 2010 Deepwater Horizon oil spill had a requirement for open data access from the outset. This is now a large-scale ocean science program supporting hundreds of scientists around the world, and all are required to submit their data so that it is directly available at the time of publication. A great many of these publications are in AGU journals, as shown in the example below from Tomàs et al. [2017].

On their website you can search for data from 246 research groups and 2,546 people! That is quite a large subset of the ocean science community. There have been no cases of data theft or of job mobility, the vicissitudes of aging and human tragedy causing loss of results. In short, the system works well.
It is AGU policy and a requirement in JGR: Oceans, as well as the all the other journals, that all our publications have behind them the data to back up the published findings. That’s the right thing to do.
—Peter Brewer, Editor-in-Chief of JGR: Oceans and Monterey Bay Aquarium Research Institute; email: [email protected]
Citation:
Brewer, P. (2017), “Do you expect me to just give away my data?”, Eos, 98, https://doi.org/10.1029/2018EO081175. Published on 14 September 2017.
Text © 2017. The authors. CC BY-NC-ND 3.0
Except where otherwise noted, images are subject to copyright. Any reuse without express permission from the copyright owner is prohibited.