
How do you define fairness? Well, who’s doing the defining, and what do they mean by fair, anyway?
About a decade ago, data scientists began developing guiding principles meant to ensure that digital data sets are fair—or, rather, FAIR. FAIR stands for findability, accessibility, interoperability, and reusability, the four qualities related to scientific data management and stewardship on which the FAIR principles focus. The overarching purposes of making data FAIR are to support open science and to maximize reuse of digital data.
Assessing how well data sets align with the FAIR principles—that is, defining FAIRness—remains a challenge.
There are 15 FAIR Guiding Principles covering three unique high-level entities, or categories: “data (or any digital object), metadata (information about that digital object), and infrastructure” (Table 1). Specifically, these principles aim to optimize data sharing in a machine-friendly environment across systems, disciplines, and regional boundaries by laying out a set of the behaviors that digital data objects should exhibit [Wilkinson et al., 2016, 2022].
The rapid uptake and adoption of the FAIR Guiding Principles by policymakers (e.g., in the European Union (EU) and Australia), funders such as the EU Commission, organizations including AGU, and research data communities worldwide have resulted in the creation of substantial data stewardship and compliance requirements for publicly funded projects and research data repositories. However, even with the desired behaviors enumerated, assessing how well data sets align with the FAIR principles—that is, defining FAIRness—remains a challenge. The principles themselves were not originally intended to be used in evaluating whether a digital data object is FAIR [Mons et al., 2017], and in an attempt to be technology and discipline neutral, they do not prescribe mechanisms to achieve the desired behaviors [Wilkinson et al., 2022].
To address needs for evaluating FAIRness, a range of useful FAIR assessment frameworks have been developed recently. However, these frameworks have different focuses and use different criteria and indicators, so their results are often inconsistent or not directly comparable. This difficulty with comparability has motivated the creation of a set of uniform, or harmonized, indicators of FAIRness.
Variation Among Frameworks
Two prominent FAIR assessment frameworks are those developed by Wilkinson et al. [2019] and by the Research Data Alliance (RDA) [RDA FAIR Data Maturity Model Working Group, 2020; Bahim et al., 2020]. As an example of how these frameworks vary and why they may not provide comparable assessments, let’s consider how each treats the original four FAIR principles related to accessibility (i.e., FAIR-A) as defined by Wilkinson et al. [2016] (Table 1), which include the following:
A1. (Meta)data are retrievable by their identifier using a standardized communications protocol.
A1.1. The protocol is open, free, and universally implementable.
A1.2. The protocol allows for an authentication and authorization procedure, where necessary.
A2. Metadata are accessible, even when the data are no longer available.
Table 1. The 15 Original FAIR Data Guiding Principles, as Established by Wilkinson et al. [2016], Covering Three Unique Entities, or Categories: Data, Metadata, and Infrastructure
| Principle Number | Principle ID | Description | Data | Metadata | Infrastructure |
| 1 | F1 | (Meta)data are assigned a globally unique and eternally persistent identifier | ✓ | ✓ | |
| 2 | F2 | Data are described with rich metadata (defined by R1 below) | ✓ | ✓ | |
| 3 | F3 | Metadata clearly and explicitly include the identifier of the data they describe | ✓ | ✓ | |
| 4 | F4 | (Meta)data are registered or indexed in a searchable resource | ✓ | ✓ | ✓ |
| 5 | A1 | (Meta)data are retrievable by their identifier using a standardized communications protocol | ✓ | ✓ | ✓ |
| 6 | A1.1 | The protocol is open, free, and universally implementable | ✓ | ||
| 7 | A1.2 | The protocol allows for an authentication and authorization procedure, where necessary | ✓ | ||
| 8 | A2 | Metadata are accessible, even when the data are no longer available | ✓ | ||
| 9 | I1 | (Meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation | ✓ | ✓ | |
| 10 | I2 | (Meta)data use vocabularies that follow FAIR principles | ✓ | ✓ | |
| 11 | I3 | (Meta)data include qualified references to other (meta)data | ✓ | ✓ | |
| 12 | R1 | (Meta)data are richly described with a plurality of accurate and relevant attributes | ✓ | ✓ | |
| 13 | R1.1 | (Meta)data are released with a clear and accessible data usage license | ✓ | ✓ | |
| 14 | R1.2 | (Meta)data are associated with detailed provenance | ✓ | ✓ | |
| 15 | R1.3 | (Meta)data meet domain-relevant community standards | ✓ | ✓ |
“Protocol” in this context refers to the mechanism or infrastructure for requesting and retrieving digital information (e.g., the hypertext transfer protocol secure, or HTTPS, for securely exchanging information across the Internet), and an “identifier” is a unique string of characters that identifies a given digital object (e.g., the digital object identifier, or DOI, of a scientific study).
Wilkinson et al. [2019] provided a set of 15 machine-interoperable FAIRness metrics, or maturity indicators (MIs). These indicators do not cover all the original principles, but recognizing that assessing FAIR has different requirements in different communities [Mons et al., 2017], the developers also established a system allowing users to create “domain-relevant community-specific MIs.” The framework’s MIs—for the FAIR-A principles, for example—tend to be infrastructure-centric (Table 2, two left-hand columns). In addition, data and metadata are not separated in MI definitions; for example, Gen2_MI_A1.1 asks whether data and metadata are retrievable using an open-source and royalty-free protocol. In practice, though, the protocols used to retrieve data and metadata may not be the same, so it is beneficial to assess the openness of each separately.
Table 2. Two Examples of FAIRness Assessment Frameworks and Their Indicators for FAIR-Accessible (FAIR-A) Principles
| Wilkinson et al. [2019] | RDA FAIR Data Maturity Model [2020] | ||
| Principle ID | Description | Principle ID | Description |
| Gen2_MI_A1.1 | Open protocol for (meta)data retrieval | RDA-A1-01M | Metadata contain information to enable the user to get access to the data |
| Gen2_MI_A1.2 | Protocol supports authentication/authorization | RDA-A1-02M | Metadata can be accessed manually (i.e., with human intervention) |
| Gen2_MI_A2 | Policy for metadata persistence | RDA-A1-02D | Data can be accessed manually (i.e., with human intervention) |
| RDA-A1-03M | Metadata identifier resolves to a metadata record | ||
| RDA-A1-03D | Data identifier resolves to a digital object | ||
| RDA-A1-04M | Metadata are accessed through a standardized protocol | ||
| RDA-A1-04D | Data are accessible through a standardized protocol | ||
| RDA-A1-05D | Data can be accessed automatically (i.e., by a computer program) | ||
| RDA-A1.1-01M | Metadata are accessible through a free access protocol | ||
| RDA-A1.1-01D | Data are accessible through a free access protocol | ||
| RDA-A1.2-01D | Data are accessible through an access protocol that supports authentication and authorization | ||
| RDA-A2-01M | Metadata are guaranteed to remain available after data are no longer available | ||
The RDA FAIR Data Maturity Model Working Group [2020], aiming to allow direct comparison of assessment results, made the first systematic attempt to provide a common set of core FAIR MIs [Bahim et al., 2020]. This framework, the most comprehensive so far, contains 41 indicators. (The FAIRsFAIR project used a subset of 17 of these to create an automated tool to evaluate the FAIRness of data sets.) However, some subjective interpretations that are out of the scope of the original FAIR Guiding Principles have been embedded in the RDA indicators set. For example, it includes additional requirements for human accessibility of data and metadata (e.g., RDA-A1-02D and RDA-A1-02M; Table 2, two right-hand columns), whereas the FAIR principles explicitly focus on ensuring the abilities of computers to act autonomously [Mons et al., 2017]. Furthermore, the RDA FAIR MIs tend to be (meta)data-centric compared with the original principles. For example, the subject of the original A1.1 and A1.2 principles is “the protocol,” whereas the subject of the corresponding MIs (RDA-A1.1-01M, RDA-A1.1-01D, and RDA-A1.2-01D) is either “data” or “metadata.” In addition, the elements of a protocol being “open” and “universally implementable” spelled out in principle A1.1 are not included in the corresponding RDA MIs.
Different interpretations of the FAIR principles tend to lead to different assessment models, resulting in vastly different assessment results.
The details of these two sets of FAIR-A assessment indicators, as captured in Table 2, clearly reveal their variation not only from the original FAIR principles but also from each other. Thus, although each framework is useful and beneficial, it is very difficult to cross compare their resulting assessments directly.
Such observations are not limited to these two FAIRness frameworks. Indeed, it has been noted that different interpretations of the FAIR principles tend to lead to different assessment models [Bahim et al., 2020], resulting in vastly different assessment results [Peters-von Gehlen et al., 2022; Wilkinson et al., 2022].
Therefore, there is an urgent and practical need for a complete set of harmonized indicators that adhere to the original FAIR Guiding Principles and can be used as fundamental building blocks of any FAIRness assessment framework. Such indicators, if broken down to the most granular level, will be beneficial to data stewards and repositories when they are developing their own FAIRness evaluation workflows or reporting FAIR compliance. And they will be essential in creating a consistent, standardized means of documenting, sharing, and integrating the FAIRness evaluation outcomes across tools and systems.
Deriving Harmonized Indicators
So how do we craft a set of fundamental, harmonized FAIRness indicators? One possible approach, which I am developing and briefly describe here, involves grammatically decomposing the original 15 FAIR Guiding Principles.
First, the relevant categories in each principle are determined: data (D), metadata (M), and infrastructure (IS; Table 1). This breakdown results in a total of 29 expected FAIR behaviors, or category-specific requirements, with 12, 13, and 4 requirements in the D, M, and IS categories, respectively. The category-specific requirements are then decomposed further into new category-specific indicators by identifying the objective noun(s) and any verb or object modifiers in the original guiding principles.
The process is outlined in Figure 1, using the FAIR-A1 principle as an example. In this case, all three categories are relevant, resulting in three category-specific requirements. Identifying the objective nouns (“data identifier,” “metadata identifier,” and “communications protocol”) and modifiers (“standardized”) then leads to the following four indicators:
A1-01D. Data identifier resolves to the digital data object.
A1-01M. Metadata identifier resolves to the digital metadata object.
A1-01IS. Communication protocol for data retrieval is standardized.
A1-02IS. Communication protocol for metadata retrieval is standardized.
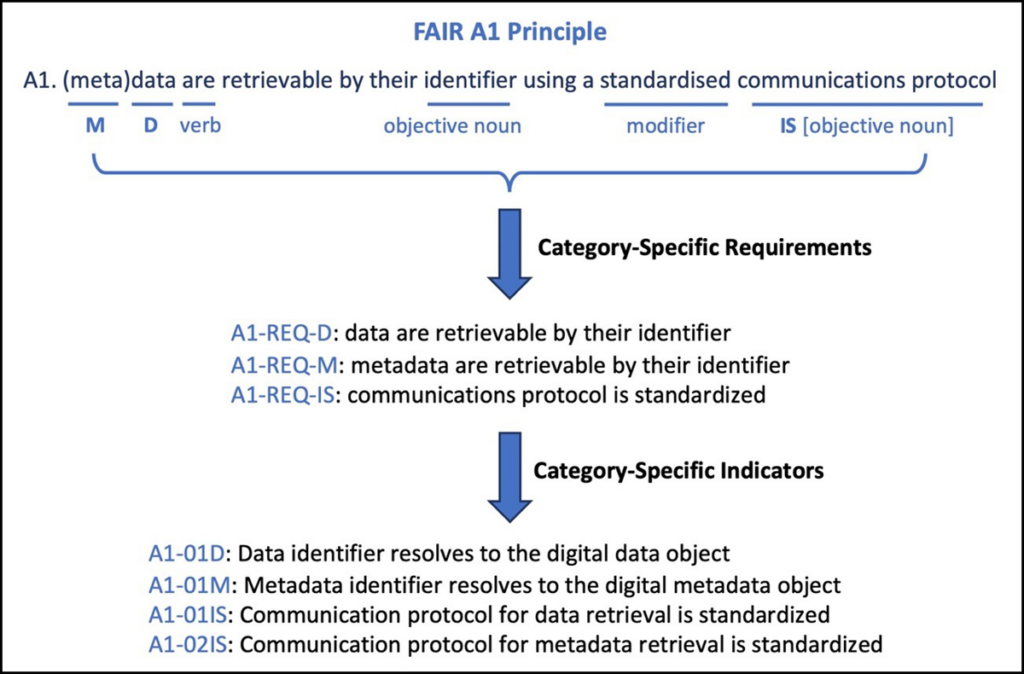
In total, this approach results in a complete set of about 80 basic indicators that together decompose the 15 FAIR principles to the most granular level possible and do not introduce additional indicators out of the scope of the original principles. Some of the indicators, although consistent with those in existing frameworks, offer subtle differences. For example, A1-01D (A1-01M) above is almost identical to RDA-A1-03D (RDA-A1-03M; Table 2), but the slight clarification in the article (“the” versus “a”) denotes the requirement in this case for the data (metadata) identifier to resolve specifically to its corresponding digital data (metadata) object.
Ultimately, these category-specific indicators are intended to be systematic and consistent with the definitions of the original FAIR principles, as well as granular and modular. These qualities mean they can be used to develop FAIRness assessment workflows for any unique application or perspective while still allowing direct comparison of assessment results from each indicator for different digital data objects regardless of the workflow.
Adding Extensions
Even with an approach to decomposing the FAIR Guiding Principles fully and consistently, there are nuances that require additional consideration. Notably, several concepts, including “rich metadata,” “qualified references,” and “relevant attributes,” are mentioned but not explicitly defined in the original FAIR principles because of their disciplinary dependency (Table 1). For example, principle 2 under findability (F2) stipulates that “data are described with rich metadata,” and principle 1 under reusability (R1) stipulates that “(meta)data are richly described with a plurality of accurate and relevant attributes.”
Ultimately, individual research disciplines or communities may each need to find their own consensus on the appropriate meaning of these terms. However, the concepts can still be included in a harmonized approach to evaluating FAIRness. Because they are not explicitly defined, the relevant indicators can be classified as “FAIR extension indicators.”
Regarding the mention of “rich metadata” in F2, for example, in addition to assessing whether the metadata included with a data object include the data usage license and data provenance, I recommend using extension indicators that assess whether these metadata also include attributes that support discovery, data retrieval, and data access. Similarly, for R1, I recommend using extension indicators that assess whether metadata include attributes describing past or potential uses of a data set as well as other contextual information and information about data processing (i.e., all information that improves data reusability and reproducibility of results).
The specific attributes desired in each case might vary by discipline or application but could include, for example, links to the metadata records of previous releases of a data product, which help preserve these records even if the previous releases are taken offline. Other relevant attributes may include data quality flags and uncertainty estimates, which can be critical to downstream applications.
Meeting an Urgent Need
A harmonized set of fundamental indicators that works across fields and applications is urgently needed.
Considering the growing demand for consistently assessing the FAIRness of digital data sets and resources, along with the evident differences among existing assessment frameworks, a harmonized set of fundamental indicators that works across fields and applications is urgently needed. Systematically decomposing the original FAIR Guiding Principles is an effective approach to producing such granular and widely adaptable indicators. With a uniform assessment framework at hand, institutions and individuals who produce or manage data will have the tools they need to meet their obligations to ensure and demonstrate that their data are, indeed, as findable, accessible, interoperable, and reusable as possible.
Acknowledgments
G.P. is supported by NASA through the Marshall Space Flight Center (MSFC) Interagency Implementation and Advanced Concepts Team (IMPACT) project under a cooperative agreement with the University of Alabama in Huntsville (NASA grant NNM11AA01A). For more detailed information about decomposing the FAIR principles into harmonized indicators and for a complete list of the indicators, please visit this page or contact the author. Generation 2 (Gen 2) MIs from Wilkinson et al. [2019] are considered in this article. A GitHub page offers more information about these MIs, and an online FAIRness evaluation tool based on these MIs is available. The version of the Research Data Alliance’s FAIR Data Maturity Model considered here is the one released in June 2020.
References
Bahim, C., et al. (2020), The FAIR Data Maturity Model: An approach to harmonise FAIR assessments, Data Sci. J., 19(1), 41, https://doi.org/10.5334/dsj-2020-041.
Mons, B., et al. (2017), Cloudy, increasingly FAIR; revisiting the FAIR data guiding principles for the European Open Science Cloud, Inf. Serv. Use, 37, 49–56, https://doi.org/10.3233/ISU-170824.
Peters-von Gehlen, K., et al. (2022), Recommendations for discipline-specific FAIRness evaluation derived from applying an ensemble of evaluation tools, Data Sci. J., 21(1), 7, https://doi.org/10.5334/dsj-2022-007.
RDA FAIR Data Maturity Model Working Group (2020), FAIR Data Maturity Model: Specification and guidelines, Res. Data Alliance, Zenodo, https://doi.org/10.15497/rda00050.
Wilkinson, M. D., et al. (2016), The FAIR Guiding Principles for scientific data management and stewardship, Sci. Data, 3, 160018, https://doi.org/10.1038/sdata.2016.18.
Wilkinson, M. D., et al. (2019), Evaluating FAIR maturity through a scalable, automated, community-governed framework, Sci. Data, 6, 174, https://doi.org/10.1038/s41597-019-0184-5.
Wilkinson, M. D., et al. (2022), Community-driven governance of FAIRness assessment: An open issue, an open discussion [version 1; peer review: approved with reservations], Open Res. Europe, 2, 146, https://doi.org/10.12688/openreseurope.15364.1.
Author Information
Ge Peng ([email protected]), Earth System Science Center, University of Alabama in Huntsville