
The Earth sciences present uniquely challenging problems, from detecting and predicting changes in Earth’s ecosystems in response to climate change to understanding interactions among the ocean, atmosphere, and land in the climate system. Helping address these problems, however, is a wealth of data sets—containing atmospheric, environmental, oceanographic, and other information—that are mostly open and publicly available. This fortuitous combination of pressing challenges and plentiful data is leading to the increased use of data-driven approaches, including machine learning (ML) models, to solve Earth science problems.
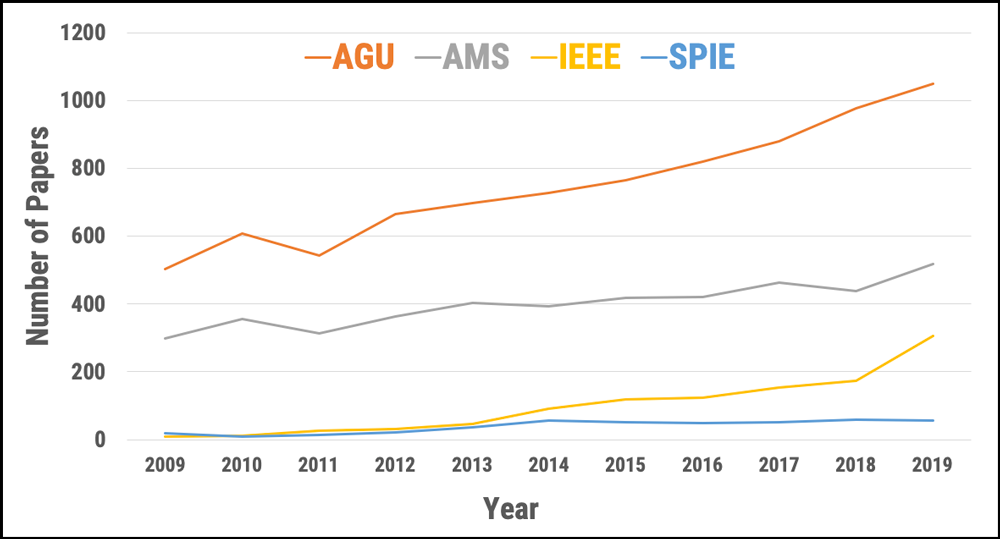
Machine learning, a type of artificial intelligence (AI) in which computers learn from data, has been applied in many domains of Earth science (Figure 1). Such applications include land cover and land use classification [Jin et al., 2019], precipitation and soil moisture estimation [Kolassa et al., 2018], cloud process representations in climate models [Rasp et al., 2018], crop type detection and crop yield prediction [Wang et al., 2019], estimations of water, carbon, and energy fluxes between the land and atmosphere [Alemohammad et al., 2017], spatial downscaling of satellite observations, ocean turbulence modeling [Sinha, 2019], and tropical cyclone intensity estimation [Pradhan et al., 2018], among others [Zhu et al., 2017].
Machine learning can discover patterns and trends buried within vast volumes of data that are not apparent to human analysts.
Machine learning uses a bottom-up approach in which algorithms learn relationships between input data and output results as part of the model-building effort, so it is not always easy to interpret the outputs of the resulting models. However, ML can discover patterns and trends buried within vast volumes of data that are not apparent to human analysts.
In traditional Earth science modeling, researchers use a top-down approach based on our understanding of the physical world and the laws that govern it. This approach allows us to interpret model outputs, yet it can be limited by the sheer amount of computing power required to solve large problems and by the difficulty of finding patterns where we don’t expect them.
Recent efforts by Earth scientists have focused on integrating the best aspects of physics-based modeling and machine learning, incorporating physical laws into ML model architectures to help build models that are easier to interpret.
Complex Problems and Complex Models
Advances in ML and in its applications to Earth science problems have enabled us to tackle complex challenges [Karpatne et al., 2019]. Machine learning techniques learn relationships among physical parameters from both input and output data, in contrast to traditional or physical modeling methods in which modelers explicitly account for those relationships when they set up a model.
Machine learning can involve either supervised or unsupervised learning. Supervised learning techniques, which are especially useful in the Earth sciences, “train” ML algorithms using labeled data sets, which contain sample data that have been tagged with a target parameter. The algorithm can use an answer key to evaluate its accuracy in interpreting the training data. In unsupervised approaches, users feed unlabeled data to the algorithm, which tries to make sense of the data by extracting patterns on its own.
After training supervised ML models (i.e., estimating model parameters), applying the models to new data is fast and cheap. Speed and economy offer a distinct advantage over many physical models in Earth science, which must be inversely solved (causes are calculated from observed effects) and require significant time and computational resources for each application.
Numerical Models, Real-World Constraints
Machine learning models can be combined with physical constraints to bridge the gap between data-driven methods and physical modeling and to increase the interpretability of ML models.
Interpreting ML model outputs and assessing why a model produces a specific output from a set of inputs can be difficult. However, the latest research shows that ML models can be combined with physical constraints to bridge the gap between data-driven methods and physical modeling and to increase the interpretability of ML models [Reichstein et al., 2019; Brenowitz and Bretherton, 2018].
These advancements are encouraging; however, there are several challenges in adopting ML for the broader Earth science community (Figure 2). Specifically, high-priority challenges include
- a lack of publicly available benchmark training data sets across all science disciplines
- a lack of interoperability among data sources, types, and formats (e.g., standard data formats for computer vision algorithms may be different from the standard formats for commonly used Earth science models)
- limited availability of baseline pretrained models that can be customized for various types or modes of Earth observations
- label or target values that are not usually structured, such as oceanic measurements from drifting buoys that cannot be adapted easily to the grid systems commonly used in ML algorithms
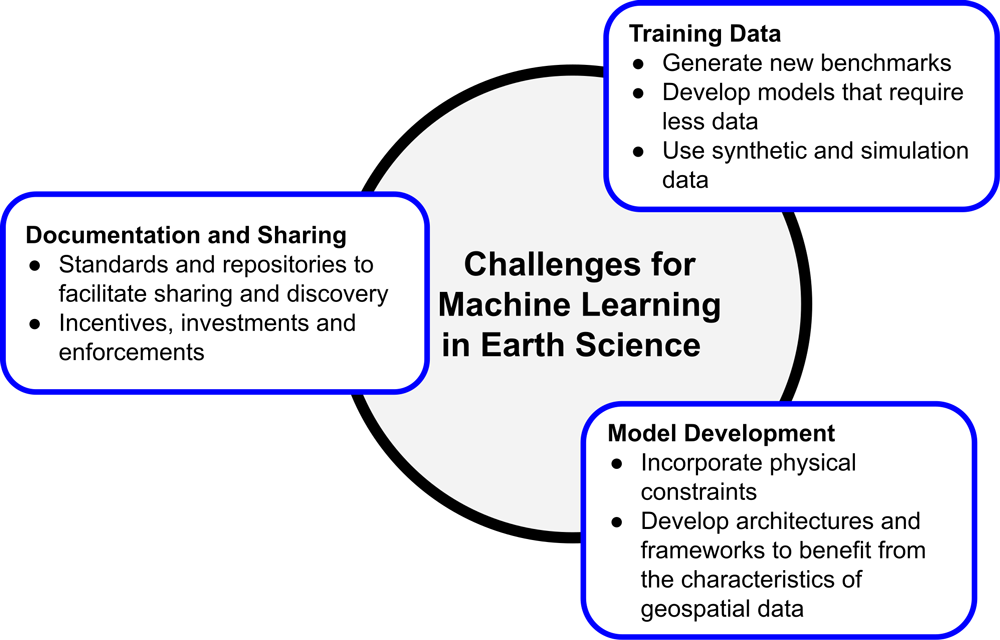
The Earth observation and ML communities would benefit from further collaborations to address these challenges and develop innovative solutions to geoscience problems. To promote such collaborations, NASA’s Earth Science Data Systems (ESDS) Program and Radiant Earth Foundation hosted a workshop last January in Washington, D.C., that gathered 51 scientists, practitioners, and experts from government agencies, nonprofit organizations, universities, and private industries. Workshop participants presented and discussed recent advances in ML techniques as well as their applications to Earth science problems.
Three working group sessions reviewed existing gaps in knowledge and tools, and they provided recommendations to facilitate applications of ML to Earth observation data. In particular, participants created a set of recommendations to develop an ML “pipeline” involving training data generation, model development and documentation, and sharing these models and data sets. The full report from the workshop is now available online.
A Need for Training Data
Generating and publishing benchmark training data sets that researchers can use to build better models are key to accelerating ML innovation. The shortage of available training data is the main bottleneck in advancing applications of ML in the Earth sciences. These data are used to estimate model parameters and are thus the building blocks of an ML model. But generating new training data sets is an extensive and, in some cases, expensive process.
Because of the importance of training data, new investments are required to support existing efforts focused on training data generation and maintenance. These investments should focus on broadening the availability of training data sets that represent the diversity of problems within relevant science disciplines.
NASA ESDS has already invested in its competitive programs to generate high-quality training data sets that are open and easily sharable. ESDS has also started to invest in challenges to develop benchmark models for existing training data sets. ESDS policies require the resulting training data sets, models, and source code to be open and free for public use.
It is also essential to increase research and investment in techniques such as active learning and semi-supervised learning, which require less training data than supervised ML approaches. Other avenues for potential innovation involve the use of synthetic training data generated by models (in contrast to using observations) and the use of training data from physical model simulations.
Complicating the effort to construct ML training data sets is the fact that Earth science data have diverse properties that are not always consistent or interoperable. Satellite observations and models, for example, provide multiband and multimode data that do not always include the three spectral bands typical for imagery data in the computer vision community. And ground observations are sometimes captured in a Lagrangian reference system—in which the observer follows an individual particle as it travels through space and time—rather than the common Eulerian system, in which the observer remains stationary. To use these data in ML models properly, new architectures and frameworks must be developed and adopted by the community.
Physically Aware Machine Learning Models
Because extreme weather events and impacts of climate change are rare or unseen in training data gathered from historical observations, machine learning models usually struggle to provide accurate predictions of scenarios involving such events or impacts.
Because ML techniques learn patterns from data and do not incorporate physical laws (e.g., mass and energy balance), they typically cannot extrapolate beyond the range of parameters learned from the training data set used. The inability to extrapolate is a challenge for expanding ML-based applications in the Earth sciences. For example, because extreme weather events and impacts of climate change are rare or unseen in training data gathered from historical observations, ML models usually struggle to provide accurate predictions of scenarios involving such events or impacts [Rasp et al., 2018].
In recent years, several approaches have been implemented to embed physical constraints in either ML model architectures or the cost function (which helps the model make itself more accurate) during training. These approaches have shown promising results in estimating atmospheric convection, sea surface temperature, and vegetation dynamic modeling. Further research is needed to build and expand physics-aware ML models in the Earth sciences.
Documentation and Sharing
Machine learning research benefits from fast iterations (i.e., rapid fitting and tuning) on various model architectures and data features. Enabling innovation in this field therefore requires thorough and proper documentation as well as sharing training data sets and models so that different researchers can trace and replicate the work others have done. Workshop participants highly recommended following the FAIR (findable, accessible, interoperable, and reusable) data management principles for cataloging ML training data and models.
Machine learning model and training data catalogs should include sufficient metadata in a standard format to facilitate their discovery and retrieval. Existing data catalog standards, such as the SpatioTemporal Asset Catalog, work well for and enable cataloging of various types of geospatial data. But more research is needed to overcome limitations of such standards for use cases such as storing nonraster data (data stored as vectors rather than in rows and columns). Moreover, the research community needs to adopt similar catalog standards for storing ML models to streamline model sharing among different groups.
Incentives and Investments
As a result of the January workshop, the assembled members of the Earth observation and ML communities made recommendations for meeting challenges in adopting and accelerating ML in the Earth sciences.
To further facilitate sharing of data sets and models, incentives should be provided to researchers and developers, and new investments are needed to support collaborative efforts for developing and maintaining open-source scientific software. Incentives may include recognition by the researchers’ organizations (especially at academic institutions), legal support to ensure intellectual property rights and proper use of their work by others, and proper citation mechanisms. Investment may be in the form of grants that specifically support development and deployment of applications and open access training data and models. Stricter policies for sharing training data and models by scientific journals and funders are essential as well.
If these recommendations are accepted and acted upon, we are confident that the continued application of ML to the wealth of Earth observation data available will produce answers for many pressing questions and problems in Earth science facing us today.
Acknowledgments
The workshop was sponsored by NASA ESDS with cosponsorship from the IEEE Geoscience and Remote Sensing Society and Clark University (with support from the Omidyar Network and PlaceFund). Radiant Earth Foundation organized the workshop, prepared the report, and provided the venue.
References
Alemohammad, S. H., et al. (2017), Water, Energy, and Carbon with Artificial Neural Networks (WECANN): A statistically based estimate of global surface turbulent fluxes and gross primary productivity using solar-induced fluorescence, Biogeosciences, 14(18), 4,101–4,124, https://doi.org/10.5194/bg-14-4101-2017.
Brenowitz, N. D., and C. S. Bretherton (2018), Prognostic validation of a neural network unified physics parameterization, Geophys. Res. Lett., 45(12), 6,289–6,298, https://doi.org/10.1029/2018GL078510.
Jin, Z., et al. (2019), Smallholder maize area and yield mapping at national scales with Google Earth Engine, Remote Sens. Environ., 228, 115–128, https://doi.org/10.1016/j.rse.2019.04.016.
Karpatne, A., et al. (2019), Machine learning for the geosciences: Challenges and opportunities, IEEE Trans. Knowl. Data Eng., 31(8), 1,544–1,554, https://doi.org/10.1109/TKDE.2018.2861006.
Kolassa, J., et al. (2018), Estimating surface soil moisture from SMAP observations using a neural network technique, Remote Sens. Environ., 204, 43–59, https://doi.org/10.1016/j.rse.2017.10.045.
Pradhan, R., et al. (2018), Tropical cyclone intensity estimation using a deep convolutional neural network, IEEE Trans. Image Process., 27(2), 692–702, https://doi.org/10.1109/TIP.2017.2766358.
Rasp, S., M. S. Pritchard, and P. Gentine (2018), Deep learning to represent subgrid processes in climate models, Proc. Natl. Acad. Sci. U. S. A., 115(39), 9,684–9,689, https://doi.org/10.1073/pnas.1810286115.
Reichstein, M., et al. (2019), Deep learning and process understanding for data-driven Earth system science, Nature, 566(7743), 195–204, https://doi.org/10.1038/s41586-019-0912-1.
Sinha, A. (2019), Temporal variability in ocean mesoscale and submesoscale turbulence, Ph.D. thesis, Columbia Univ., New York, https://doi.org/10.7916/d8-bngk-r215.
Wang, S., et al. (2019), Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques, Remote Sens. Environ., 222, 303–317, https://doi.org/10.1016/j.rse.2018.12.026.
Zhu, X. X., et al. (2017), Deep learning in remote sensing: A comprehensive review and list of resources, IEEE Geosci. Remote Sens. Mag., 5(4), 8–36, https://doi.org/10.1109/MGRS.2017.2762307.
Author Information
Manil Maskey, Earth Science Data Systems, NASA Headquarters, Washington, D.C.; Hamed Alemohammad ([email protected]), Radiant Earth Foundation, San Francisco, Calif.; Kevin J. Murphy, Earth Science Data Systems, NASA Headquarters, Washington, D.C.; and Rahul Ramachandran, NASA Marshall Space Flight Center, Huntsville, Ala.
Citation:
Maskey, M.,Alemohammad, H.,Murphy, K. J., and Ramachandran, R. (2020), Advancing AI for Earth science: A data systems perspective, Eos, 101, https://doi.org/10.1029/2020EO151245. Published on 06 November 2020.
Text not subject to copyright.
Except where otherwise noted, images are subject to copyright. Any reuse without express permission from the copyright owner is prohibited.
Text not subject to copyright.
Except where otherwise noted, images are subject to copyright. Any reuse without express permission from the copyright owner is prohibited.