Editors’ Highlights are summaries of recent papers by AGU’s journal editors.
Source: Journal of Advances in Modeling Earth Systems
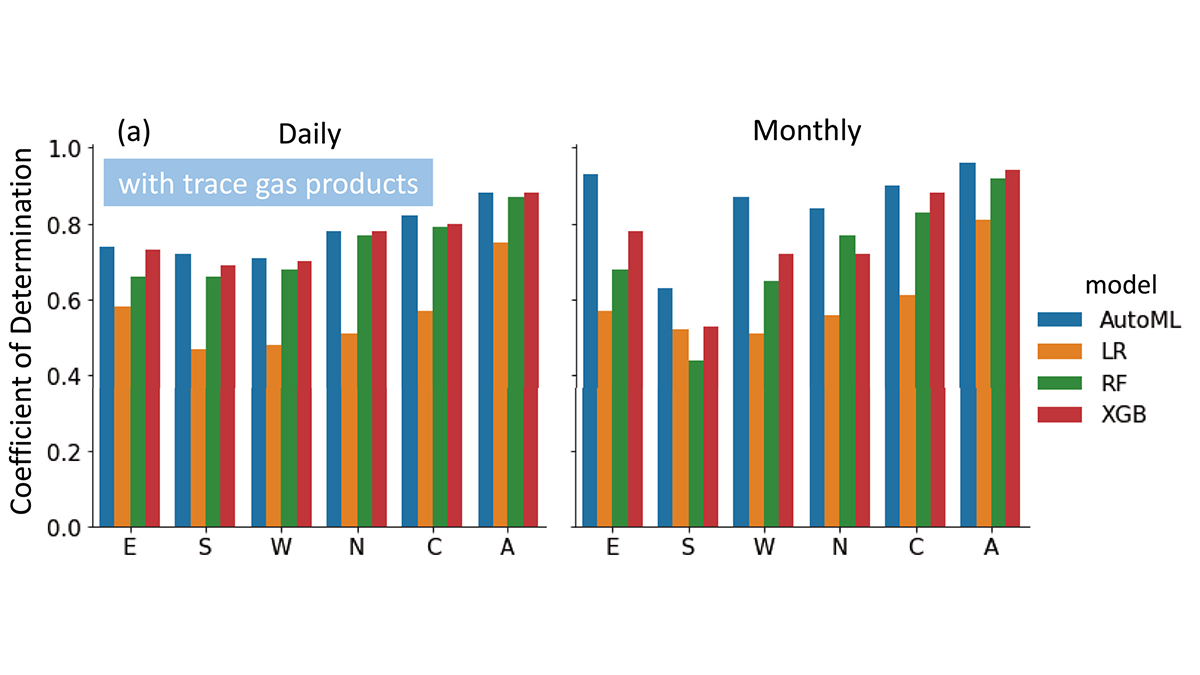
Despite the fact that Machine Learning (ML) facilitates knowledge discovery in atmospheric and environmental research, findings are likely to be influenced by the performance of the trained ML models. However, no single ML algorithm and hyperparameter configuration (e.g. the number of decision trees) can be the optimal solution for all problems. Those who tune the hyperparameters of Random Forest (RF) may overlook the possibility of a better model from eXtreme Gradient Boosting (XGBoost), and vice versa.
Zheng et al. [2023] present a workflow that identifies important variables empowered by the Automated Machine Learning (AutoML) framework FLAML (a Fast and Lightweight AutoML library). This workflow suggests that atmospheric composition (as indicated by columns of tropospheric trace gases) contains signatures of PM2.5 precursors and improves surface PM2.5 estimates in India.
AutoML automatically tunes the hyperparameters and selects the “best model”, which the authors demonstrate to be at least as good as the user-chosen models and can serve as a baseline. It liberates domain scientists from selecting learners and hyperparameters and can prevent suboptimal choices due to idiosyncrasies or ad-hocness. Therefore, the AutoML-enabled workflow has the potential to be the best practice of machine learning applications for atmospheric and environmental research.
Citation: Zheng, Z., Fiore, A. M., Westervelt, D. M., Milly, G. P., Goldsmith, J., Karambelas, A., et al. (2023). Automated machine learning to evaluate the information content of tropospheric trace gas columns for fine particle estimates over India: A modeling testbed. Journal of Advances in Modeling Earth Systems, 15, e2022MS003099. https://doi.org/10.1029/2022MS003099
—Jiwen Fan, Editor, JAMES