
Editors’ Vox is a blog from AGU’s Publications Department.
Scientists have been measuring earthquakes for hundreds of years. As instruments have advanced, so has our understanding of how and why the ground moves. A recent article published in Reviews of Geophysics describes how the Big Data revolution is now advancing the field of seismology. We asked some of the authors to explain how seismic waves are measured, how measurement techniques have changed over time, and how big data is being collected and used to advance science.
In simple terms, what is seismology and why is it important?
Seismology is a science that is based on vibrational waves (‘seismic waves’) that travel through the Earth. Seismic waves produce ground motions that are recorded by seismometers. Recorded ground motions can provide vital clues both about the sources of waves (e.g., earthquakes, volcanoes, explosions, etc.) and about the properties of the Earth the waves travel through. Seismology provides tools for understanding the physics of earthquakes, for monitoring natural hazards, and for revealing the internal structure of the Earth.
Seismology provides tools for understanding the physics of earthquakes, for monitoring natural hazards, and for revealing the internal structure of the Earth.
How does a seismometer work and what important advancements in knowledge have been made since their development?
It’s surprisingly hard to accurately measure the motion of the ground because any instrument that does so must also move with the ground (otherwise it would have to be in the air, where it couldn’t directly record ground motion). To deal with this challenge, seismometers contain a mass on a spring that remains stationary (an ‘inertial mass’), and they measure the motion of the instrument relative to that mass. Early seismometers were entirely mechanical, but it’s hard to design a mechanical system where the inertial mass stays still over a range of frequencies of ground motion.
A key advancement was the use of electronics to keep the mass fixed and therefore record a much wider range of frequencies. An ideal seismometer can record accurately over a broad band of frequencies and a wide range of ground motion amplitudes without going off scale. This is easier said than done, but seismometers are improving every year.
What is the difference between passive and exploration seismology?
Passive seismology is about recording the seismic waves generated by natural or existing sources like earthquakes. Passive seismologists typically deploy instruments for a long time in order to gather the data they need from the spontaneous occurrence of natural sources of seismic waves. In contrast, exploration seismologists generate their own seismic waves using anthropogenic sources like explosions, air guns, or truck vibrations. Because they control the timing and location of the source of seismic waves, exploration seismologists typically work with large numbers of instruments that are deployed for a short time. Exploration seismology is most widely used in the oil industry but can also be used for more general scientific purposes when high resolution imaging is needed.
How have advances in seismologic methods improved subsurface imaging?
Developments in seismic imaging techniques are allowing seismologists to significantly improve the resolution of images of the subsurface. A particularly powerful technique for high resolution imaging is called Full-Waveform Inversion (FWI). FWI uses the full seismogram for imaging, trying to match data and model “wiggle for wiggle” rather than only using simplified measures like travel times, and can thus provide better image resolution. The method has become widely adopted by the exploration seismology community for this reason and is now becoming more common in the passive seismic community as well.
Another important innovation in imaging uses persistent sources of ambient noise like ocean waves to image the subsurface. This is particularly useful for short-term deployments where there is often insufficient time to wait around for natural sources like earthquakes to occur.
What is “big data” and how is it being used in seismology?
‘Big Data’ is a relative term that defines data containing greater variety, with larger volumes or coming in at a faster rate, which requires different data analysis methods and technologies than ‘small data’. In seismology, the volumes of data being acquired from individual experiments are now reaching hundreds of terabytes in passive seismology, and petabytes in exploration seismology. For perspective, a typical laptop has less than one terabyte of disk storage. The velocity of data is the rate at which it is acquired or analyzed. In seismology, a new measurement technique called Distributed Acoustic Sensing (DAS) can fill a 1 terabyte hard drive in approximately 14 hours. The variety of data being used for seismic investigations is also increasing, with complementary data types like GNSS, barometric pressure, and infrasound becoming more commonly combined with seismic data.
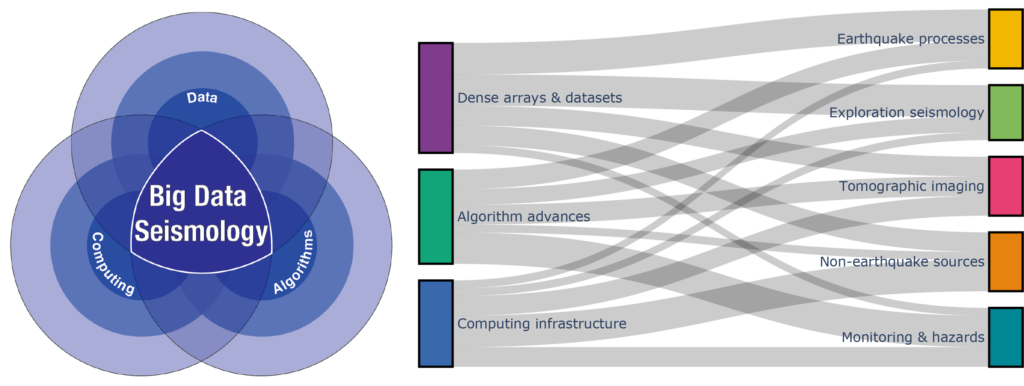
What are the main drivers of Big Data Seismology?
There are three main drivers. First, innovations in sensing systems are allowing seismologists to conduct ‘big data’ experiments. Second, new data-hungry algorithms such as machine learning and deep neural networks are enabling seismologists to scale up their data analysis and extract more meaning from massive seismic datasets. Third, advances in computing are allowing seismologists to apply data-hungry algorithms to big data experiments. Parallel and distributed computing allow scientists to perform many computations simultaneously, with calculations often split across multiple machines, and cloud computing services provide researchers with access to on-demand computing power.
Moving forward, what are some of the challenges and opportunities that Big Data seismologists face?
In terms of challenges, the first relates to handling large amounts of data. Most seismologists are accustomed to easily accessing and sharing data via web services, with most of their processing and analysis of the data done on their own computers. This workflow and the infrastructure that supports it doesn’t scale well for Big Data Seismology. Another challenge is obtaining the skills that it takes to do research with big seismic datasets, which requires expertise not only in seismology but also in statistics and computer science. Skills in statistics and computer science are not routinely part of most Earth Science curricula, but they’re becoming increasingly important in order to do research at the cutting edge of Big Data Seismology.
The opportunities are wide-ranging, and our paper discusses many opportunities for fundamental science discovery in detail, but it’s also hard to anticipate all the discoveries that will be made possible. Our best guide is to look back at the history of seismology, where many major discoveries have been driven by advances in data. For instance, the discovery of the layers of Earth followed the development of seismometers that were sufficiently sensitive to measure teleseismic earthquakes. The discovery of the global pattern of seismicity – which played a key part in the development of the theory of plate tectonics – was preceded by the development of the first global seismic network. The first digital global seismic network was followed by our first images of the convecting mantle. If we take the past as our guide, we can anticipate that the era of Big Data Seismology will provide the foundation for creative seismologists to make new discoveries.
—Stephen J. Arrowsmith ([email protected];  0000-0002-9150-0363), Southern Methodist University, USA; Daniel T. Trugman (0000-0002-9296-4223), University of Nevada, Reno and University of Texas at Austin, USA; Karianne Bergen (0000-0003-2474-9115), Brown University, USA; and Beatrice Magnani (0000-0002-5357-8784), Southern Methodist University, USA
0000-0002-9150-0363), Southern Methodist University, USA; Daniel T. Trugman (0000-0002-9296-4223), University of Nevada, Reno and University of Texas at Austin, USA; Karianne Bergen (0000-0003-2474-9115), Brown University, USA; and Beatrice Magnani (0000-0002-5357-8784), Southern Methodist University, USA
Editor’s Note: It is the policy of AGU Publications to invite the authors of articles published in Reviews of Geophysics to write a summary for Eos Editors’ Vox.