
Over the past decade, data from Earth and environmental research have dramatically increased in volume, complexity, and diversity, but in many cases, efforts to make these data usable and accessible have not kept pace. This data proliferation has created an urgent need for data preservation, curation, quality checks, and standards for enabling cross-disciplinary use of the data.
Earth scientists use environmental data to develop knowledge about Earth’s processes, parametrize and test site- to global-scale models, and provide information needed for effective planning related to energy, environment, and infrastructure. These scientists need long-term, spatially dense, high-quality observational data sets coupled with simulations to understand and predict ecosystem behavior over timescales spanning decades to centuries.

Yet in many projects, data management is an afterthought, primarily conducted to satisfy demands from research sponsors or journals that published data be openly accessible. This ad hoc approach results in important data sets remaining unarchived, inaccessible, or unusable.
To overcome these trends, emerging community repositories are enabling scientists to easily archive and publish data with essential metadata as part of the scientific workflow. These repositories increasingly serve a critical role in enhancing data sharing and use.
A new data archive seeks to play this role for the U.S Department of Energy’s (DOE) environmental science community. The new archive, called Environmental Systems Science Data Infrastructure for a Virtual Ecosystem (ESS-DIVE), preserves, expands access to, and improves usability of data from the DOE’s research in terrestrial and subsurface environments.
ESS-DIVE’s Vision and Scope
ESS-DIVE was established with a vision of advancing the scientific understanding and prediction of hydrobiogeochemical ecosystem processes by providing long-term stewardship and enabling usage of data from research in the DOE’s Environmental System Science (ESS) domain. ESS data sets include the Terrestrial Ecosystem Science and Subsurface Biogeochemical Research programs. The multidisciplinary ESS-DIVE team consists of computer scientists, environmental scientists, and digital librarians from Lawrence Berkeley National Laboratory (LBNL) and the National Center for Ecological Analysis and Synthesis (NCEAS).
The data stored in ESS-DIVE will be critical to understanding and predicting how our terrestrial and subsurface environments function and evolve.
ESS-DIVE’s data services launched on 1 April 2018. The archive stores data generated by field, experimental, and modeling activities in environments spanning bedrock through soil and vegetation to the atmospheric interface (Figure 1). ESS-DIVE also serves data sets that were previously stored in the Carbon Dioxide Information Analysis Center (CDIAC) data archive [e.g., Andres et al., 2014; Le Quéré et al., 2016]. The main copies of the data are stored at DOE’s National Energy Research Scientific Computing Center (NERSC) supercomputing facility, and backup copies are stored elsewhere.
The data stored in ESS-DIVE will be critical to understanding and predicting how our terrestrial and subsurface environments function and evolve. The DOE’s environmental research is conducted by large interdisciplinary teams that couple field observations and experiments with modeling exercises. Thus, the data sets generated are extremely diverse, comprising various sciences that include hydrology, geology, ecology, geochemistry, biology, climate, and geophysics, and they can be used for several purposes.
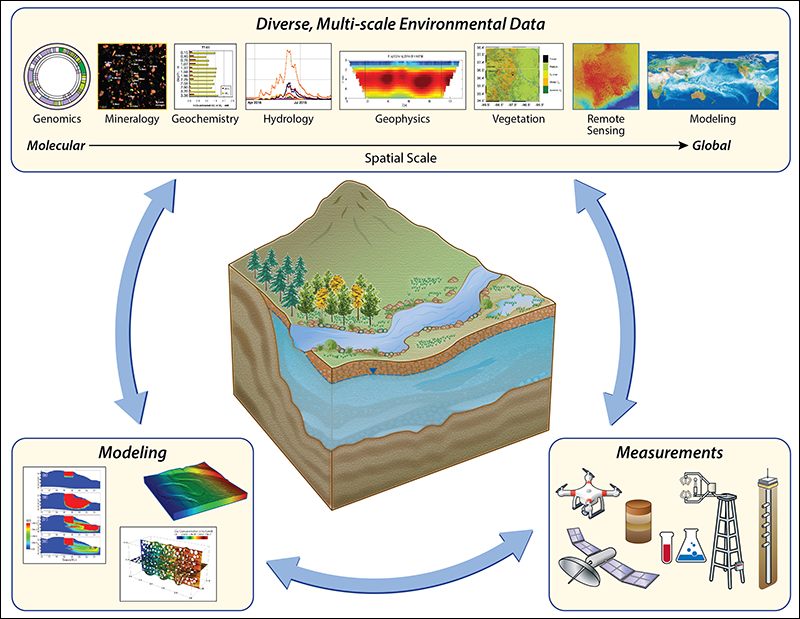
For example, the DOE’s observational data sets can inform the scientific understanding of important processes such as nutrient and water cycling and land-atmosphere carbon and energy interactions. The model results predict how ecosystems such as watersheds, Arctic landscapes, and forests will drive and respond to global and environmental changes. The data in ESS-DIVE can also extensively be used to evaluate process and global and regional Earth system models through tools like the International Land Model Benchmarking (ILAMB) project. ESS-DIVE will serve as a resource for a wide variety of stakeholders, including scientists, policy makers, water utilities, farmers, and environmental remediation managers.
Archive Design and Features
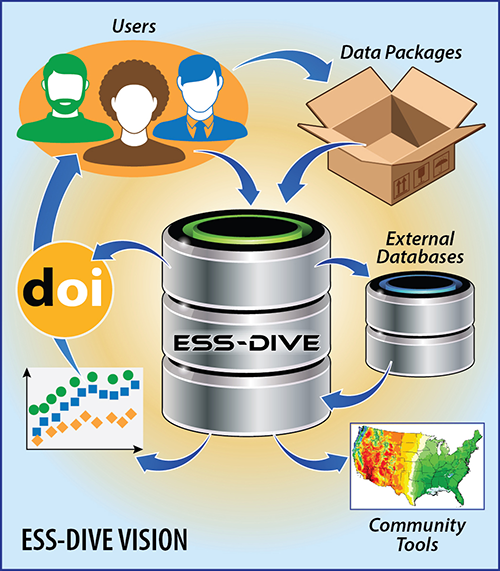
ESS-DIVE is designed using Findable, Accessible, Interoperable, and Reusable (FAIR) principles [Wilkinson et al., 2016], and it incentivizes data generators to contribute well-structured, high-quality data for long-term preservation. Contributors can archive and record versions of their data and metadata in standardized formats and release data publicly with digital object identifiers (DOIs; Figure 2). Data consumers can easily search for and access data and metadata. As a member node of the Data Observation Network for Earth (DataONE), ESS-DIVE makes its data secure—ensuring that the data sets are preserved over the long term—and discoverable in cross-catalog searches.
ESS-DIVE stores “data packages”: collections of related data files and metadata. A data package may contain individual or multiple linked data sets such as time series from a sensor or sensor network, data from a field campaign or experiment, data products and analysis codes, and model setup and simulation results. Metadata collected about the package are indexed for search and retrieval. Metadata include such fields as the title, abstract, authors, keywords, data usage rights, project and funding details, spatial and temporal coverages, and methods.
We offer two licenses as usage rights for public data: the Creative Commons Attribution (CC BY-4.0) and the Creative Commons Public Domain (CC0). Package metadata are made available under the CC0 license to enable reuse by DataONE and other search catalogs.
Architecture and Strategies for Data Serving
ESS-DIVE is based on a two-part architecture. The front-end user services infrastructure provides data access, data contribution and publishing, tracking of data downloads, and other user-facing tools. The current implementation involves a Web portal built on top of Metacat, a repository software developed by NCEAS. Metacat stores metadata using the Ecological Metadata Language (EML) standard [Fegraus et al., 2005], and it provides a Web application programming interface (API) to facilitate input and retrieval of data packages and an engine to query across a number of metadata attributes [Berkley et al., 2001].
The back-end data preservation infrastructure guarantees data availability and provides the underlying support for data packages, which includes integrity checks, replication, metadata indexing and management, and alternate means of access (e.g., via an API). All basic components of the architecture run inside Docker containers [Merkel, 2014], which make multiple copies (redundant instances) available if the main copy is unavailable during maintenance or in the event of a hardware or software failure.
The primary ESS-DIVE instance runs on NERSC’s Spin platform, which is a Docker-based system designed for building and hosting scalable Web services integrated to high-performance computing resources [Snavely et al., 2018]. Copies of all data and metadata are replicated to an LBNL Information Technology Division server. Copies are also replicated via Metacat to NCEAS and the DataONE federation, guaranteeing broadly redundant availability.
ESS-DIVE Data Life Cycle
Researchers can upload and manage their data on ESS-DIVE using a data-publishing cycle that involves a series of steps (the numbers below correspond to those in Figure 3):
- An authorized contributor logs into ESS-DIVE, uploads data files, and enters relevant metadata.
- The user submits the data package, which is assigned a unique system identifier. The package is visible to only the user, and it can be continually revised.
- When the package is ready, the user submits a request to publish it. An ESS-DIVE administrator curates the data package, works with the user to complete metadata quality checks, and assigns a DOI (except when an existing DOI is specified).
- The data package becomes publicly available on the ESS-DIVE portal and federated catalogs.
- If required, the user makes revisions to the package through the ESS-DIVE version control system.
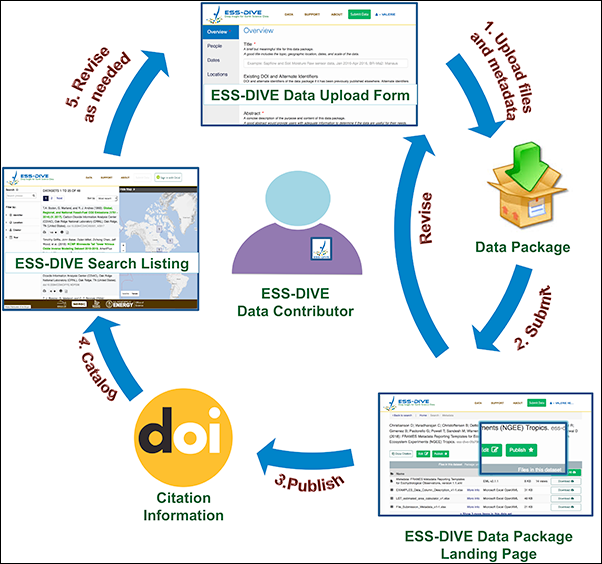
Once data are published, they become discoverable to all ESS-DIVE users. The ESS-DIVE Data Access Portal enables the search of the entire text within the metadata submitted by contributors, and it allows filtering by geographic location through a map and other criteria such as DOI, authors, keywords, and publication year.
Engaging the Community
The ESS-DIVE team is proactively engaging with the ESS scientific research community to understand their needs and to adopt or develop standards for data and metadata archiving that improve data discovery and use. We apply techniques based on user experience research in combination with agile software development cycles to determine user requirements and rapidly translate these requirements into software features [Ramakrishnan and Gunter, 2017].
We are building partnerships with our user communities across national labs and universities through site visits, seminars, and tutorials.
We are building partnerships with our user communities across national labs and universities through site visits, seminars, and tutorials. We regularly solicit input from stakeholders, including representatives from ESS projects involved in building cyberinfrastructure, and our Archive Partnership Board, which comprises the principal investigators of major ESS projects. In addition to our partnership with NCEAS/DataONE, we are engaging with the broader digital library and scientific community to keep current with data management practices and collaborate on standards.
Short- and Long-Term Outlook
The ESS-DIVE data portal allows members of the public to search published data and download files with an Open Researcher and Contributor Identification (ORCiD) account. Users can upload data using a Web form. Access to this form is currently restricted to users whose data are either directly generated by or closely related to a DOE ESS-sponsored project. Potential users seeking to preview ESS-DIVE features can use a specially designed sandbox instance to test the portal’s functionality and upload capabilities without submitting any data to ESS-DIVE. Questions, feedback, and help requests can be submitted to ess-dive-support@lbl.gov.
In the near future, we will enable programmatic data package submissions via an API and support bulk data uploads. We will also initiate work on community standards for file-level metadata.
Our long-term vision for ESS-DIVE (Figure 1) is to provide advanced queries and integrated views of data submitted in standardized formats, support community tools for data analysis and visualization, enable exchange with other databases, and enable integration with models and analyses by providing a pipeline to NERSC’s computing resources. We hope that by providing such resources to the community and making data easily accessible and useful, ESS-DIVE will be able to play a critical role in advancing ecosystem science.
Acknowledgments
ESS-DIVE is funded by the U.S. Department of Energy, Office of Science, Office of Biological and Environmental Research, Climate and Environmental Science Division, Data Management program under contract DE-AC02-05CH11231. ESS-DIVE uses resources of the National Energy Research Scientific Computing Center (NERSC), a DOE Office of Science User Facility operated under contract DE-AC02-05CH11231. We acknowledge NCEAS and the DOE Office of Scientific and Technical Information (OSTI) for assistance in accelerating ESS-DIVE’s development.
References
Andres, R. J., T. A. Boden, and D. Higdon (2014), A new evaluation of the uncertainty associated with CDIAC estimates of fossil fuel carbon dioxide emission, Tellus B, 66(1), 23616, https://doi.org/10.3402/tellusb.v66.23616.
Berkley, C., et al. (2001), Metacat: A schema-independent XML database system, in Proceedings of the Thirteenth International Conference on Scientific and Statistical Database Management: SSDBM 2001, pp. 171–179, IEEE Comput. Soc., Los Alamitos, Calif., https://doi.org/10.1109/SSDM.2001.938549.
Fegraus, E. H., et al. (2005), Maximizing the value of ecological data with structured metadata: An introduction to Ecological Metadata Language (EML) and principles for metadata creation, Bull. Ecol. Soc. Am., 86(3), 158–168, https://doi.org/10.1890/0012-9623(2005)86[158:MTVOED]2.0.CO;2.
Le Quéré, C., et al. (2016), Global carbon budget 2016, Earth Syst. Sci. Data, 8(2), 605–649, https://doi.org/10.5194/essd-8-605-2016.
Merkel, D. (2014), Docker: Lightweight Linux containers for consistent development and deployment, Linux J., 2014(239), 2, https://dl.acm.org/citation.cfm?id=2600239.2600241.
Ramakrishnan, L., and D. Gunter (2017), Ten principles for creating usable software for science, in 2017 IEEE 13th International Conference on e-Science (e-Science), pp. 210–218, IEEE Press, Piscataway, N.J., https://doi.org/10.1109/eScience.2017.34.
Snavely, C., et al. (2018), Spin: A Docker-based platform for deploying science gateways at NERSC, paper presented at Gateways 2018: The 13th Gateway Computing Environments Conference, Univ. of Texas at Austin, Austin, https://doi.org/10.6084/m9.figshare.7071770.v2.
Wilkinson, M. D., et al. (2016), The FAIR guiding principles for scientific data management and stewardship, Sci. Data, 3, 160018, https://doi.org/10.1038/sdata.2016.18.
Author Information
Charuleka Varadharajan ([email protected]), Earth and Environmental Science Area, Lawrence Berkeley National Laboratory, Berkeley, Calif.; Shreyas Cholia, Computational Research Division, Lawrence Berkeley National Laboratory, Berkeley, Calif.; also at National Energy Research Scientific Computing Center, Berkeley, Calif.; Cory Snavely, National Energy Research Scientific Computing Center, Berkeley, Calif.; Valerie Hendrix, Computational Research Division, Lawrence Berkeley National Laboratory, Berkeley, Calif.; Christina Procopiou, Diana Swantek, and William J. Riley, Earth and Environmental Science Area, Lawrence Berkeley National Laboratory, Berkeley, Calif.; and D. A. Agarwal, Computational Research Division, Lawrence Berkeley National Laboratory, Berkeley, Calif.
Citation:
Varadharajan, C.,Cholia, S.,Snavely, C.,Hendrix, V.,Procopiou, C.,Swantek, D.,Riley, W. J., and Agarwal, D. A. (2019), Launching an accessible archive of environmental data, Eos, 100, https://doi.org/10.1029/2019EO111263. Published on 08 January 2019.
Text not subject to copyright.
Except where otherwise noted, images are subject to copyright. Any reuse without express permission from the copyright owner is prohibited.