Editors’ Highlights are summaries of recent papers by AGU’s journal editors.
Source: Water Resources Research
In applied and fundamental sciences, the design of observation and monitoring networks constitutes a grand challenge. This is especially true for hydrogeologic settings dealing with subsurface flow and transport because data to develop and test monitoring design methodologies are scarce. In the past, synthetic test cases based numerical simulations of flow and transport have been used successfully; however, they suffer from the computational expense and the lack in generality.
The challenge is not unique to Earth sciences and hydrogeology in particular. For example, in the life sciences, actual patient data from clinical studies are invaluable yet because of fragmentation of data and strong legal constraints, federated data are the exception, thus hindering research progress.
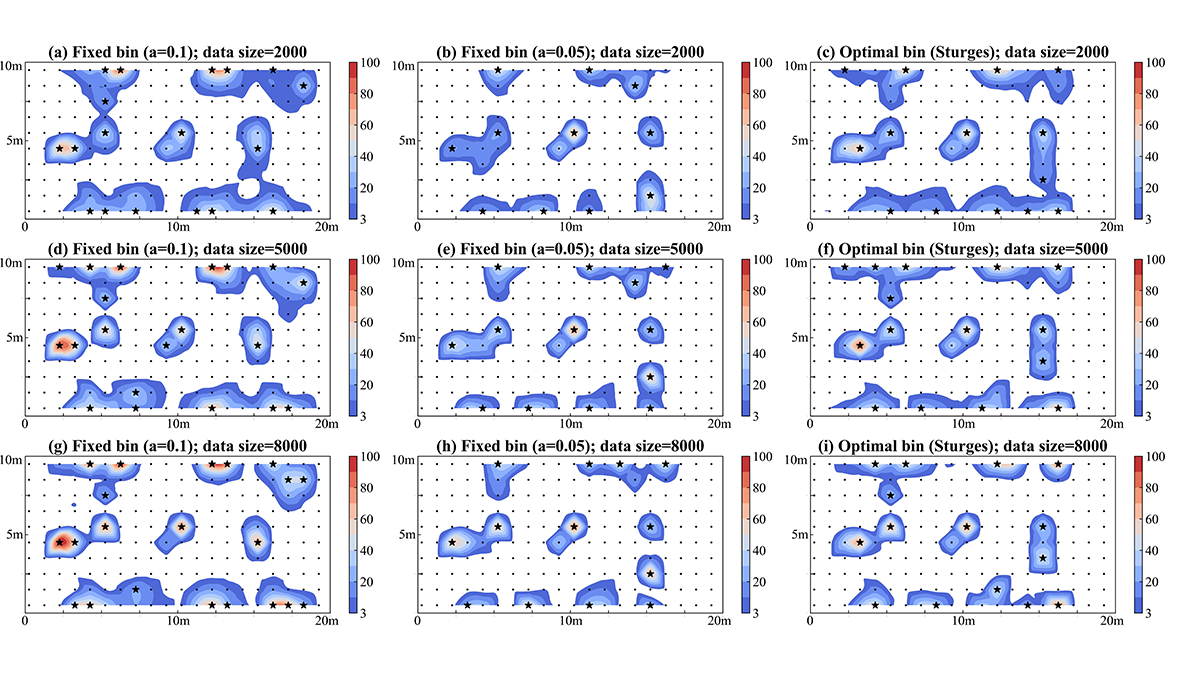
A general path forward is the construction of synthetic data or the augmentation of limited data using deep learning (DL) technologies to produce big and diverse data sets of high realism for ensuing statistical analyses. Chen et al. [2022] present a data generation and augmentation approach in which they generate a large data set using DL in combination with numerical flow and transport simulations. The resulting data set is then used in conjunction with a state-of-the-art information theory methodology for monitoring network design to arrive at a set of optimal observation locations for hydraulic head and solute concentration in a heterogeneous aquifer.
While the study is limited to a 2-D space domain and tested without application to real-world data, the usefulness and impact is clear. Applying DL to existing aquifer observations and statistical models of aquifer heterogeneity opens new avenues in generating reference data sets to develop rigorous monitoring design and inversion algorithms. In addition, the approach is general and can be applied to different types of observation network design problems in Earth sciences and beyond.
Citation: Chen, J., Dai, Z., Dong, S., Zhang, X., Sun, G., Wu, J., et al. (2022). Integration of deep learning and information theory for designing monitoring networks in heterogeneous aquifer systems. Water Resources Research, 58, e2022WR032429. https://doi.org/10.1029/2022WR032429
—Stefan Kollet, Editor, Water Resources Research