

At the end of Raiders of the Lost Ark, the mysterious Ark of the Covenant, recently recovered by Indiana Jones, is boxed up in a plain wooden crate and carted into a massive warehouse filled with countless stacks of similar crates. As the cart disappears around a corner in the warehouse, viewers are left to wonder what it would take to find the ark again.
The premise of this scene offers an apt analogy for what can happen to data—even valuable, hard-won data—stored in databases without adequate organization. For both experienced and novice scientists, navigating the information landscape to find such “hidden” data that are relevant to their research can require extraordinary efforts.
When done well, curation accelerates research progress and yields greater transparency in the scientific process and trust in scientific knowledge.
In today’s open science environment, careful curation of data, software, documents, and other elements of the scientific knowledge ecosystem is essential to helping researchers efficiently sift through the vast, ever increasing volume of information. Curation provides context and clarity around information, making it more findable and useful. Curated guidance also improves data and information accessibility. When done well, curation accelerates research progress and yields greater transparency in the scientific process and trust in scientific knowledge.
Here we explore the concept of scientific content curation and its value for enhancing the discovery and use of scientific data and information, focusing on two use cases within NASA.
What Is Scientific Content Curation?
In the art world, curation refers to the selection, organization, and presentation of works of art in a collection or exhibit. Curation can similarly refer to the organization of online content or information. In this context, content curation has been described as “the act of discovering, gathering, and presenting digital content that surrounds specific subject matter.” We build upon this and other definitions to define scientific content curation as involving authoritative experts who identify, gather, validate, synthesize, organize, and present contextual details necessary to discover, understand, and use scientific data and knowledge effectively [e.g., Rotman et al., 2012].
Essentially, scientific content curation is a value-adding effort. It includes any activity or process that accelerates progress toward actionable science or makes it easier for diverse audiences to digest scientific information. The scope of this curation is not limited to data and publications—it also includes detailed contextual information appearing in sources that often are not well preserved over time. Such sources can include gray literature that is made available outside traditional channels (e.g., scholarly journals) as well as tables, figures, diagrams of vital information, personnel lists, blogs from trusted sources, and other nonreviewed content.
Effective scientific content curation is guided by subject matter experts who validate and synthesize relevant and reliable information on given topics. These experts use a structured methodology to streamline research activities for data and information seekers. This process fosters confidence and trust among users of the curated content because they understand that trusted individuals or teams are responsible for it.
The Need for Curation
The sheer amount of information can confound and confuse anyone, especially those new to research or those delving into a new discipline.
With the continuing expansion of scientific content, advances in technology, and policies that increasingly favor open science, more data and information are available to researchers than ever before. The sheer amount of information can confound and confuse anyone, especially those new to research or those delving into a new discipline. Unfortunately, the proliferation of predatory publishers, sham societies, and bogus conferences complicates the information landscape by making it easier to disseminate authoritative-looking, but ultimately unreliable, material.
A lot of skill is required to search the mass of content to extract authoritative, authentic, and reliable data and information—a critical first step to addressing any science question. This effort can be lengthy and arduous. Researchers often repeat information collection efforts that others have done before them, diverting time and attention from other important research tasks. Through the process of identifying and providing relevant context about data and information, scientific content curation helps users navigate this vast landscape, facilitating more efficient scientific discovery by streamlining the initial research steps.
Models of successful scientific content curation are found across the sciences. The Smithsonian Astrophysical Observatory’s Astrophysics Data System and the National Museum of Natural History’s Encyclopedia of Life are good examples. Meanwhile, two ongoing NASA projects, the Catalog of Archived Suborbital Earth Science Investigations (CASEI) and the Science Discovery Engine (SDE), offer model use cases for scientific content curation in the Earth and space sciences. These efforts were each developed to meet the needs of particular communities, and in practice, they promote discovery of NASA data and information across a range of disciplines.
A Home for Suborbital Science
Since September 2018, NASA’s Airborne Data Management Group (ADMG) has been building CASEI, a scientifically curated inventory containing more than half a century of NASA Earth science observations collected from airborne and field (i.e., suborbital) campaigns to improve on existing information search capabilities. These observations have the potential to support new science investigations beyond the questions the data were originally collected to address. However, data users have reported that these observations are difficult to discover, access, and use because airborne and field investigation data are recorded in a wide variety of formats, coordinate systems, and spatiotemporal resolutions, using various data archival processes, metadata, and complex motivating and situational details [Earth Science Data Systems, 2018; Smith et al., 2020]. Furthermore, airborne and field data are stored across a distributed network of data centers, each focused on different thematic topics of study and using different approaches to data stewardship. These factors compound to create an inconsistent and cumbersome discovery process.
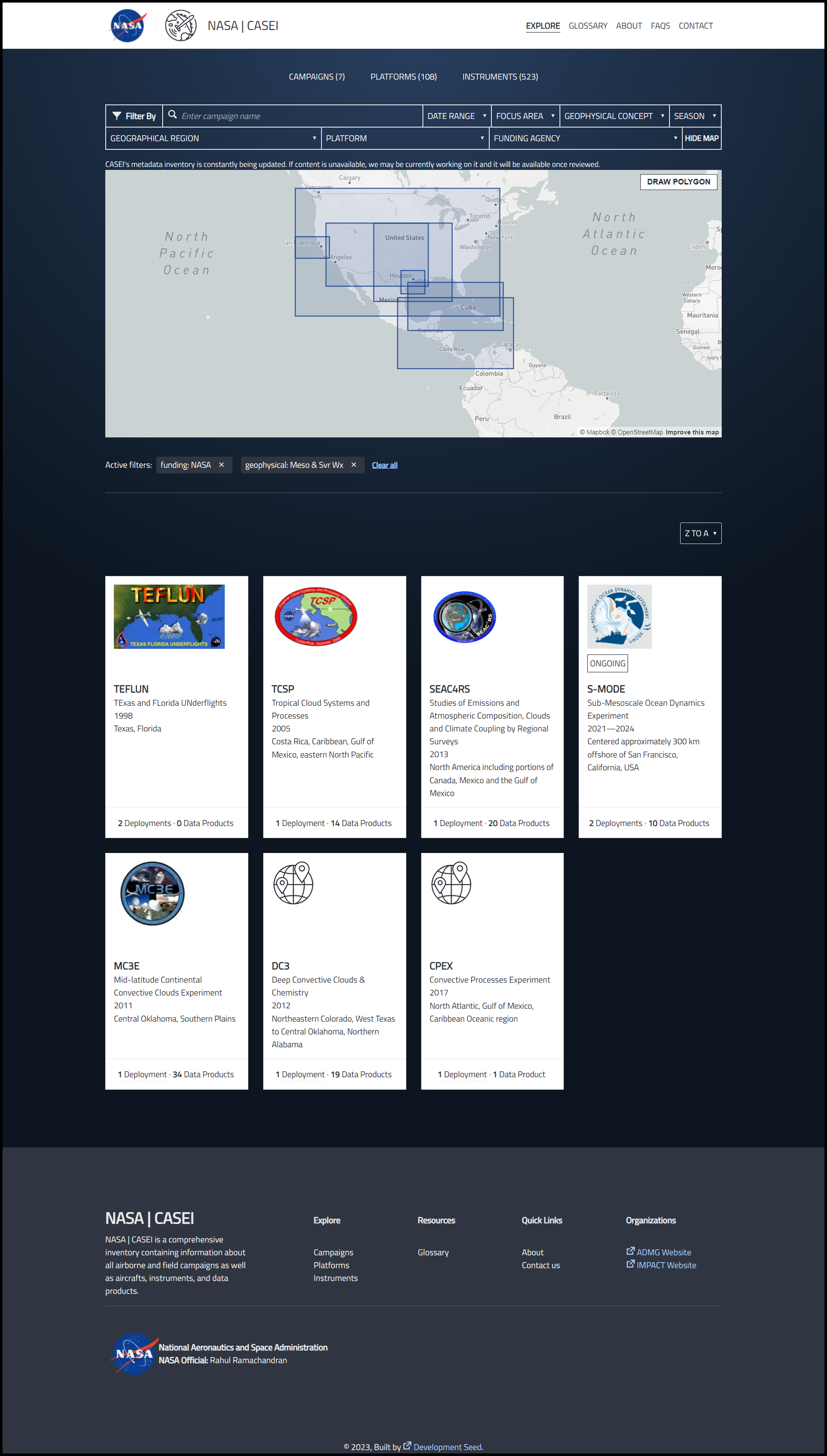
CASEI has a user-friendly application programming interface that enables users to browse, search, and filter database content easily, and it is based on a metadata model informed by user community needs. The CASEI model includes substantially more metadata content than is typically gathered for data products added to the metadata registry behind NASA’s Earthdata Search, the primary tool for searching NASA Earth science data. The additional CASEI metadata content includes regions of study, significant event descriptions, vertical region of observation, surface types, and other details that allow users to target subsets of the full data record quickly or to relate information and data across multiple campaigns. For example, imagine researchers are interested in investigating effects of aerosol and chemical species on cloud development specifically in coastal regions. Metadata in CASEI make it easy to identify existing campaigns that collected aerosol, chemistry, and cloud-targeted observations over coastal geographies.
CASEI does not host or archive data products but, rather, serves as a curation service by pointing users directly to data stored at various NASA data centers (called Distributed Active Archive Centers, or DAACs). Curation for CASEI is performed by ADMG team members who are trained in the technical aspects of CASEI curation and understand the heterogeneity and complexity of airborne and field data. The curation process begins with an examination of authoritative data and information sources such as peer-reviewed science literature, field reports, campaign event summaries, and instrument operation tables. This review helps team members gather, validate, and synthesize critical contextual metadata associated with data sets that can extend observations’ usefulness and support future science understanding via appropriate data use in new analyses.
Terms used in organizing and referring to airborne and field campaigns vary across disciplines and over time. To create the CASEI inventory, curators need to identify how to fit the existing campaign information into the catalog’s metadata model. Curators use objective decision trees to ensure they make consistent determinations in translating existing information in use to the CASEI definitions and metadata model [Wingo and Smith, 2023]. Three curators then fully review all metadata before content is published to the CASEI database.
To maintain content accuracy over time, curators complete quarterly database updates. These updates include maintaining compliance with standardized science keywords, adding new data products for active campaigns, and including URLs to new peer-reviewed publications. CASEI user interface updates and added features and capabilities are also developed on the basis of user feedback. For example, developers are currently working on adding maps containing stationary platform locations and moving platform tracks.
To date, users around the world have used the beta CASEI interface; the catalog will be officially released in July 2023.
An Engine for Discovery
NASA’s Science Mission Directorate (SMD) encompasses studies in five broad topical areas: astrophysics, biological and physical sciences, Earth science, heliophysics, and planetary science. A large variety of data, documents, images, models, tools, software, and code across these topics exists under the umbrella of SMD, but it is scattered across numerous archives, repositories, and websites, making data and information discovery a challenge.
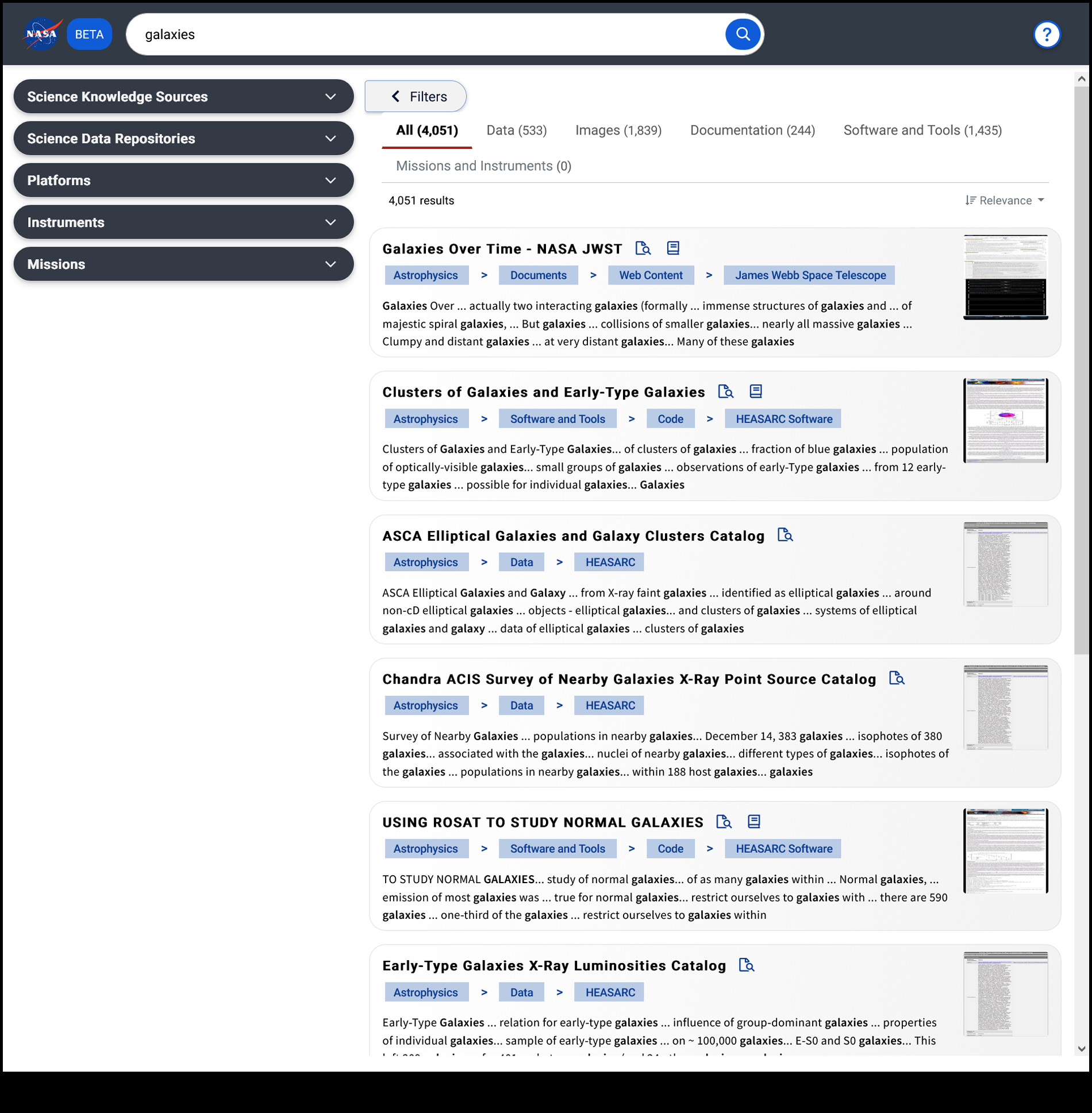
Starting in early 2022, NASA’s Open-Source Science Initiative developed SDE to support the agency’s goals of increasing the availability, discoverability, and accessibility of open, interdisciplinary information. SDE provides a single access point for curated data and resources from across SMD’s five subject areas. Flexible filtering options—which currently include platforms, instruments, and missions and will be expanded to include other key concepts—provide a layer of organization and guide users to explore SDE content more effectively. With SDE, a user searching for information about galaxies could, for example, filter resources by specific platforms, such as the Hubble and James Webb space telescopes.
Curation for the Science Discovery Engine involves collaboration with subject matter experts to identify and add contextual knowledge.
The curation process for SDE involves collaboration with subject matter experts to identify and add contextual knowledge to relevant tools, documents, data and image metadata archives, code repositories, and software available in existing, but scattered, locations. This task is challenging and time-consuming because of the sheer volume of information and because data and information are sometimes duplicated at multiple sites, websites go unmaintained, and web links are broken.
Content curation at SDE is ongoing as more data and resources are identified and incorporated. In addition, the SDE team curates the search term lists within each filtering option. Significant effort is required to create and maintain the term list for each filter, which synthesizes existing terms across SMD’s scientific topic areas, but the context these filters provide is invaluable for new users.
The beta SDE, which is regularly growing as more content is added, was released at AGU Fall Meeting 2022 in Chicago and currently holds more than 700,000 searchable documents, including 84,000 metadata records about data.
The Scientific Content Curation Cycle
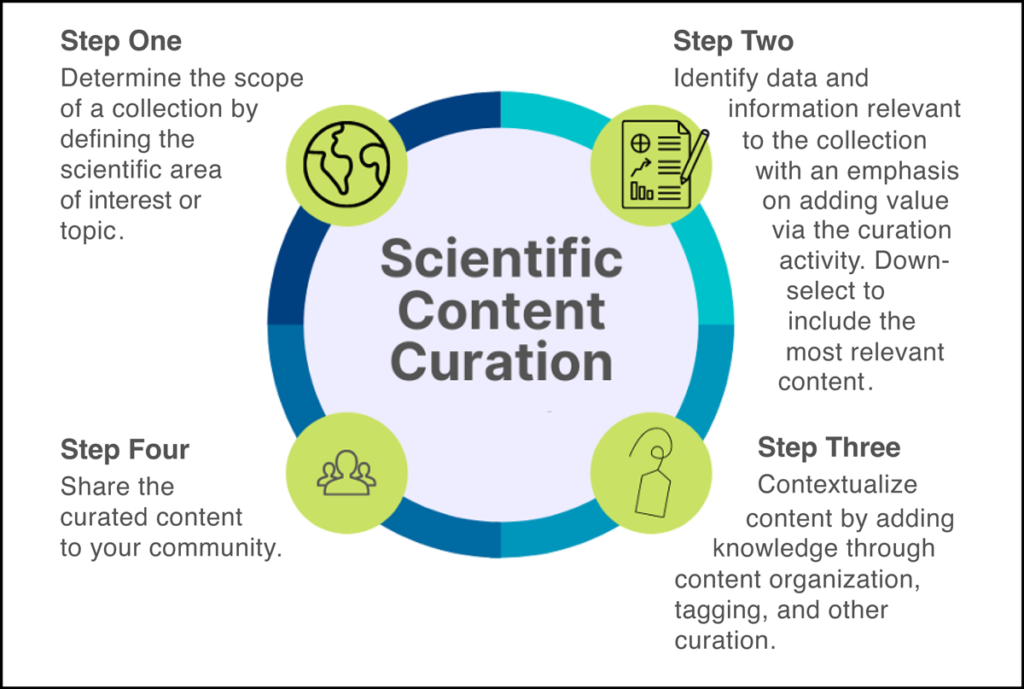
Scientific content curation works best as a living activity that is repeated over time (Figure 1). The cycle begins with the identification of a need or use case from the community. The use case highlights trends, topics of discussion, or gaps in knowledge and is essential for defining the scope of a curation effort. For example, creation of SDE was driven by an identified need to ease discovery of NASA’s open science data and information and enable interdisciplinary science.
Once the use case is defined, human subject matter experts and/or artificial intelligence (AI) techniques are applied to identify related data and information and add value for users by selecting only the most relevant content. Further value and knowledge are added to this content through effective organization, annotation, visualization, and distillation of information into more understandable formats [Dale, 2014].
A curated collection is then shared with the user community—via integrated search platforms, web pages, online learning environments, or crowdsourced science portals—to enhance understanding of and access to the information. Community feedback drives additional content creation, beginning the curation cycle again.
There is a delicate balance between the scientific value gained through maintaining curated content and the costs of doing so.
Maintenance is essential to ensuring that a collection remains up-to-date and continues to bring value to the community. There is a delicate balance, however, between the scientific value gained through maintaining curated content and the costs of doing so. On the one hand, a curated collection represents a focused source of reliable knowledge and a significant investment of time and effort that should be recognized, valued, and incentivized. Ensuring the longevity of collections, along with the ability to cite them, aids in recognizing curator contributions and provides transparency and trust for users.
On the other hand, the costs associated with maintaining a curated collection indefinitely, which include those of the necessary infrastructure and the added effort to keep a collection fresh and relevant, can potentially become unsustainable. For example, since 2016, administrators of the Climate Data Initiative (CDI) [Ramachandran et al., 2016], a curated collection of federal government data relevant to climate change questions, have struggled to maintain the collection with the minimal support they receive. CDI originally curated more than 700 data sets but now maintains only 570.
Many questions go into the considerations of whether and how long to maintain curated resources. What commitments must be made to preserve them? Are decisions driven by metrics alone—and if so, what metrics—or are there other factors to weigh? And how can community needs for information be met most efficiently and with potentially limited support?
The Future of Curation
Scientific content curation takes many forms, including the following:
- aggregating existing information that’s relevant to a use case (as in SDE, CASEI, and CDI)
- thoughtfully distilling aggregated content to guide users to enhanced understanding (as in Earthdata Pathfinders)
- bringing together new or previously unconnected content (e.g., curation around a topic like “landslides across the solar system”) to create new perspectives
- developing new content to enhance existing curation efforts (e.g., adding campaign timelines to CASEI)
- applying AI and machine learning techniques to improve curation efficiency (as in ES2Vec [Ramasubramanian et al., 2020], an Earth science–specific adaptation of Word2Vec, which transforms individual words into numerical representations for use in an AI algorithm)
Given the exponential growth in information availability, as well as growing pushes to improve transparency and equitable access to science outcomes, scientific content curation in all its forms is becoming increasingly vital. It is no longer feasible for a single human to effectively search through and assess the vast amounts of information available on a topic. New curation approaches are being identified and leveraged as state-of-the-art technologies are developed and as more, sometimes underserved, communities join scientific efforts. These new approaches are helping scale up curation efforts to keep up with content growth and demands for rapid open access to data and information.
Recently, AI, machine learning, and natural language processing (NLP) have shown promise; examples include the use of NLP to improve gene annotations and text mining techniques to curate biomedical research [Ohyanagi et al., 2015; Alex et al., 2008]. However, for AI to be effective, it must be used in tandem with human expertise to train AI algorithms and validate their outputs.
The scientific and data management communities must prioritize scientific content curation, which means recognizing and rewarding contributors’ efforts, valuing the process, and preserving the outcomes.
Ensuring that this human expertise is available is a challenge. Scientists already face mounting demands on their time, including vying for increasingly competitive and constrained financial support and meeting expectations for faster, more open scientific outputs. Participating in curation as a subject matter expert only increases existing responsibilities. So how can we continue engaging scientists in this work?
As a start, the scientific and data management communities must prioritize scientific content curation, which means recognizing and rewarding contributors’ efforts, valuing the process, and preserving the outcomes. To do this, the data management community must move beyond simply archiving data and instead focus on providing enhanced services to user communities. This involves fundamentally changing how we operate and staff repositories, with technologists and scientists working together. In addition, institutions should expect funding requests in scientific proposals to enable essential activities of scientific content curation. Finally, a method is needed to credit the work of scientific content curators—perhaps one similar to approaches for crediting work that goes into producing data sets.
Through such efforts, we can improve the long-term sustainability of well-organized, curated scientific repositories that help make sense of the vast information landscape, open more equitable access to information, and foster the interdisciplinary work needed to address many challenges facing the world today. We can also ensure that valuable, hard-won data and information don’t end up like the ark in Raiders, gathering dust in the dark and lost to time.
References
Alex, B., et al. (2008), Automating curation using a natural language processing pipeline, Genome Biol., 9, suppl. 2, S10, https://doi.org/10.1186/gb-2008-9-s2-s10.
Dale, S. (2014), Content curation: The future of relevance, Bus. Inf. Rev., 31(4), 199–205, https://doi.org/10.1177/0266382114564267.
Earth Science Data Systems (2018), Management of airborne data products: Challenges and recommendations, version: February 27, 2018, NASA, Washington, D.C.
Ohyanagi, H., et al. (2015), Plant Omics Data Center: An integrated web repository for interspecies gene expression networks with NLP-based curation, Plant Cell Physiol., 56(1), e9, https://doi.org/10.1093/pcp/pcu188.
Ramachandran, R., et al. (2016), Climate data initiative: A geocuration effort to support climate resilience, Comput. Geosci., 88, 22–29, https://doi.org/10.1016/j.cageo.2015.12.002.
Ramasubramanian, M., et al. (2020), ES2Vec: Earth science metadata keyword assignment using domain-specific word embeddings, in 2020 SoutheastCon, pp. 1–6, Inst. of Electr. and Electron. Eng., Piscataway, N.J., https://doi.org/10.1109/SoutheastCon44009.2020.9249743.
Rotman, D., et al. (2012), Supporting content curation communities: The case of the Encyclopedia of Life, J. Am. Soc. Inf. Sci. Technol., 63, 1,092–1,107, https://doi.org/10.1002/asi.22633.
Smith, D. K., et al. (2020), Construction of an airborne data inventory for improved data discoverability and access, paper presented at AMS Annual Meeting 2020, virtual, Am. Meteorol. Soc., ntrs.nasa.gov/citations/20200000477.
Wingo, S. M., and D. Smith (2023), ADMG CASEI Inventory Terms Definitions, NASA Earth Sci. Data and Inf. Syst. Stand. Coord. Off., https://doi.org/10.5067/DOC/ESCO/ESDS-RFC-047v1.
Author Information
Kaylin Bugbee ([email protected]), NASA Marshall Space Flight Center, Huntsville, Ala.; and Deborah Smith, Stephanie Wingo, and Emily Foshee, University of Alabama in Huntsville