

Earth’s climate in the past has varied substantially from what we experience today. During the Paleocene-Eocene Thermal Maximum about 56 million years ago, for example, temperatures globally were far warmer than today. Similarly, temperatures between about 4,000 and 8,000 years ago, during the mid-Holocene, were also elevated by several degrees on average. On the other hand, during the Little Ice Age, which lasted roughly from the 16th through the 19th centuries, much of the Northern Hemisphere was cooler than today.
Vast amounts of paleoclimate data have been collected over the past 4 decades from a variety of sources, such as marine sediments, speleothems, ice cores, and tree rings.
Scientists study past climates using different types of paleoclimate data to better understand the planet’s range of behavior, which informs our ideas about how it’s likely to change in the future. Vast amounts of paleoclimate data have been collected over the past 4 decades from a variety of sources, such as marine sediments, speleothems, ice cores, and tree rings. When such multitudinous data are organized into research databases, rather than being maintained as numerous individual data sets, they allow for more accurate reconstruction of past global climate variability and improve the predictive power of models of future climate. However, as academic incentives for those who collect these data are geared toward publication—and not the creation of robust databases—database creation is usually done by researchers on a volunteer basis. Thus, it is important to maximize gains from such efforts.
A number of ongoing efforts are enabling paleoclimate databases, such as the LinkedEarth Project, the PAGES (Past Global Changes) working groups, and the research community–curated data sets in Neotoma. Every similar initiative faces common challenges: for example, (1) deciding on consistent terminology and the essential metadata to be measured and reported, (2) determining how to disseminate and update this information (and how often), and (3) determining how the continuity of this process can be ensured beyond time-bound funding cycles. Past efforts have tackled these problems using different strategies. In creating a new speleothem database, the speleothem community can provide useful insights to aid in the development of additional paleoclimate databases.
Paleoclimate Proxies in Speleothems
Speleothems are inorganic cave deposits, such as stalagmites and stalactites, that form from drip waters supersaturated with respect to calcium carbonate. They are powerful climate archives because they are found in terrestrial regions around the world and yield information on the climatic and environmental conditions that prevailed during their formation. Scientists can accurately determine speleothem ages by studying the ratios of uranium and thorium isotopes they contain, and speleothems provide robust oxygen isotopic signatures that can be directly correlated with the isotopic signatures of precipitation falling above the cave, allowing reconstructions of regional atmospheric circulation patterns.
Global, community-wide efforts to synthesize speleothem data have been lacking.
In 2017, the Speleothem Isotope Synthesis and Analysis (SISAL) Working Group was created under the umbrella of PAGES to create a paleoclimate database based on 4 decades of speleothem paleoclimate research. The first version of the SISAL database was published in 2018 [Atsawawaranunt et al., 2018]; version 2 of the database, published in 2020, contains 691 records, 513 of which have additional standardized age-depth models [Comas-Bru et al., 2020] (Figure 1). (Age-depth models attribute an age to every sample taken along a speleothem’s growth axis.)
In speleothem paleoclimate research, individual research groups study stalagmites to target specific climate questions. This approach allows for great flexibility in targeting novel and unconventional research questions. But global, community-wide efforts to synthesize speleothem data and to produce oxygen isotopic maps of past climate states like the mid-Holocene and the Little Ice Age have been lacking.
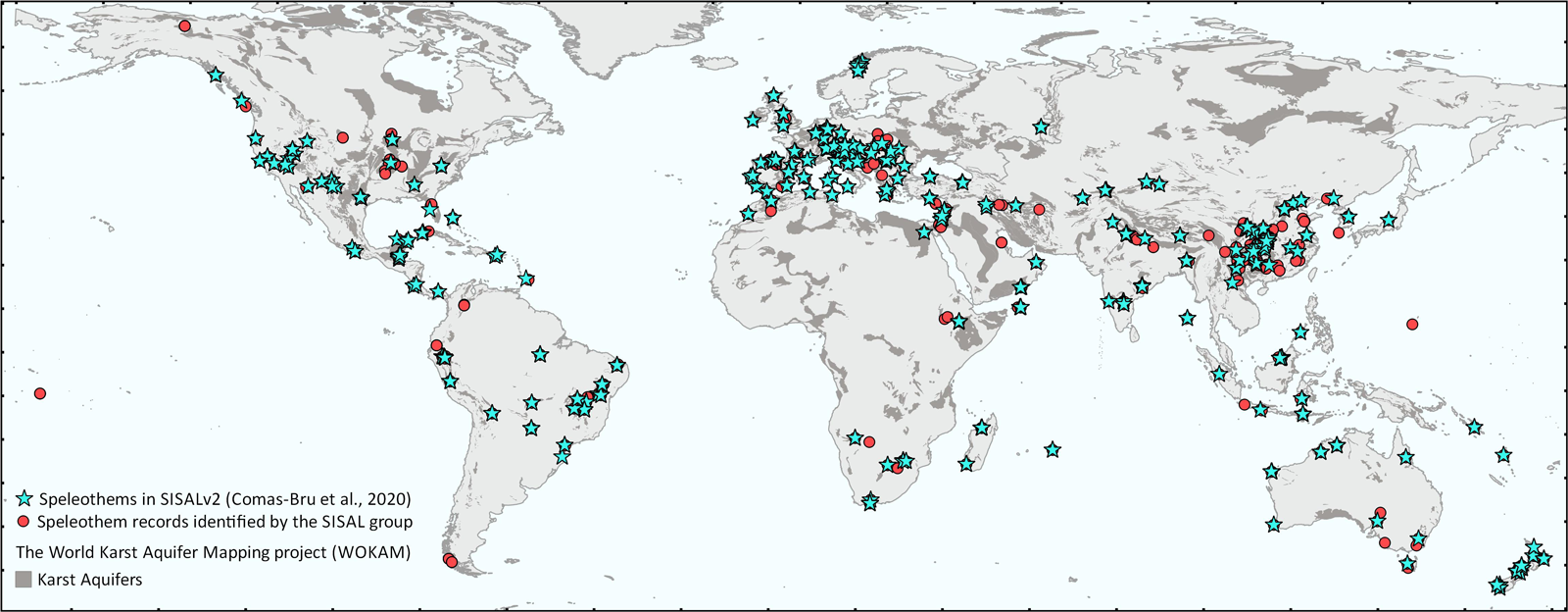
These climate states were dominated by specific climate forcings, such as high levels of solar insolation or profuse volcanic eruptions. Comparing real-world speleothem oxygen isotopic measurements with the results of climate model simulations helps identify shortcomings in the models and ultimately improves their accuracy. Such improvements are crucially important because models that represent past climate states realistically are better able to project future climate change.
Quality Control and Data Standardization
The ultimate aim of a database is to increase the ease with which a large collection of data can be accessed and used to answer research questions requiring regional or global perspectives. Before speleothem oxygen isotopic data can be used in global climate models, individual speleothem data sets must be synthesized and standardized. This process involves organizing the data with standard metadata terminology and standard reporting guidelines [e.g., Khider et al., 2019]. In addition, the data entered in the database must be accurate.

One of the selling points of SISAL’s database is that all raw data are first entered into preset data spreadsheets—by the original authors whenever possible—and then quality checked at multiple levels by SISAL coordinators and leaders to avoid data entry mistakes and for metadata completeness before the data are added to the database. Automated scripts that detect common mistakes (e.g., incorrect units of measurement) help in this process. SISAL also disseminates automated unit conversion sheets for data fields such as location coordinates and dating constants to reduce errors and improve standardization. In sum, these approaches help ensure that the SISAL database contains more comprehensive data and metadata than are typically available in public data repositories, such as NOAA’s National Centers for Environmental Information (NCEI), which do not have SISAL’s extensive data, metadata, and standardization requirements.
Scientists in the paleoclimate research community can follow different strategies to achieve metadata and data standardization, making decisions, for example, through open-access voting (e.g., as in the Future Earth Project and the Paleoclimate Community Reporting Standard) or through working groups that decide on equivalent terms to be used across archives (e.g., the PAGES2k project). The SISAL Working Group selected its initial data and metadata fields, terminology, and reporting standards on the basis of input from active speleothem researchers during a workshop in 2017 [Comas-Bru et al., 2017]. The workshop involved established experts in the field and early-career researchers from groups around the world, and in the end, input from about 100 researchers was considered until the database structure was finalized.
Since SISAL’s inception and the creation of the first database, members of the working group using the database have published research papers rapidly [e.g., Comas-Bru et al., 2019]. This consistent data usage has resulted in additional data quality control before database publication. The database also allows, importantly, for identification of metadata fields that are not systematically reported by researchers but that are necessary for reuse of the data (Table 1). For example, a researcher using the database could screen for speleothem samples with “unknown” mineralogy and then discard these samples from further analysis.
As SISAL is part of a growing number of paleoclimate databases, it is important to consider data and metadata field standardization across platforms to ensure the future continuity and usefulness of these databases. This cross-platform standardization requires a complementary approach involving long-term discussions among data generators, database managers, and the wider research communities involved, with simultaneous tracking of the data being generated and actually used for research.
| Table 1. Examples of Metadata Fields in the SISAL Database (and Available Options for Each Field) as well as Percentages of Speleothem Entries for Which Information About These Fields Was Not Provided | ||
| Data Field | Drop-Down List Options | Percentage of Records for Which This Information is “Unknown” in SISALv2 |
| Speleothem type | Stalagmite Stalactite Flowstone Composite Other Unknown |
3.0% |
| Mineralogy | Calcite Secondary Calcite Aragonite Vaterite Mixed Unknown |
2.8% |
| Drip type | Seepage flow Seasonal drip Fast flow Mixture Unknown Not applicable |
80.9% |
| δ18O water equilibrium | Yes No Unknown |
55.9% |
| Dating thickness | Not a drop-down list; percentage of individual speleothem records with no information for this field | 65.1% |
Fruitful Collaborations
SISAL has reached out beyond the speleothem community and established collaborations with researchers from other paleoclimate disciplines.
SISAL has reached out beyond the speleothem community and established collaborations with researchers from other paleoclimate disciplines. Particularly noteworthy is the success the working group has had in strategizing with members of the climate modeling community about uses of the SISAL data in data-model comparison studies [Ait Brahim et al., 2020]. This exchange has proven exceptionally fruitful for both sides and resulted in open dialogue about what spatiotemporal distributions of speleothem data are useful for modelers and, conversely, how model results can be interpreted and reconciled with the available speleothem data. For example, speleothem data in the SISAL database covering the mid-Holocene have allowed scientists to examine whether climate models accurately account for solar insolation forcing during this time [Cauquoin et al., 2019].
Collaborations among early-career researchers in the United States and around the world have proved very successful. SISAL, which has been led, coordinated, and implemented by early-career researchers, engaged scientists representing geographical diversity and in different phases of their academic careers to ensure wide accessibility and participation. Selections of workshop participants have been made on the basis of individuals’ subject expertise and geographical reach and have actively encouraged early-career researchers to lead and participate in SISAL’s efforts. We found that this approach created opportunities for early-career researchers, allowing them to stay up to date with the field and to work on internationally collaborative projects that advance both research in the field and their personal career goals. In addition, data generators and SISAL members involved in the quality-checking process get authorship in SISAL database papers, incentivizing data sharing that leads to a more comprehensive database.
SISAL workshops and collaborative projects have provided opportunities for researchers to develop a “database mindset,” which further incentivizes data standardization starting in the early stages of project design. SISAL is a relational database providing data in multiple file types (i.e., CSV and SQL) that can be mined using Python, R, MATLAB, and MySQL, among other programs. Many paleoclimate researchers are new to database querying and even to the idea of framing research questions that can be tackled using large databases. SISAL provides instructions and examples of the various querying software to facilitate this sort of broader framing, and it organized an introductory workshop (to be repeated at future conferences) focused on using the database [Ait Brahim et al., 2020].
SISAL is not a data repository, so people cannot search for an individual record in a Google-like setting. But if researchers need to find all the records of a particular age or within a particular region, they can do so easily, with a single command line in MySQL, for example. This is not something you can do with repositories like NCEI, where you would have to painstakingly download one record after another.
We believe that this format of providing a diverse range of incentives for data generators while at the same time providing validation for metadata through ongoing projects as well as different options for scientists to get credit for their work is the best way forward for research databases like SISAL and for science broadly. Top-down enforcement solely from funding bodies and publications can ensure open access to data, but the research community must build the infrastructure to make this effort effective.
Ensuring Continuity
Considering SISAL’s productivity since it began (three database versions, 14 peer-reviewed articles, and seven outreach articles), it appears this approach to database construction and management has been very successful. On the basis of communication within the research community, we believe the database now contains 75% of all speleothem records published to date.
One way of ensuring future continuity of this database is to have data generators use the standardized format established by SISAL to produce data sets that can be submitted to a peer-reviewed or community-curated repository.
However, the creation and curation of the database is supported by time-limited grants whose terms will soon end, meaning the SISAL Working Group will no longer be available to encourage data submission, quality check data, or update the database. One way of ensuring future continuity of this database is to have data generators use the standardized format (i.e., the preset spreadsheets) established by SISAL to produce data sets that can be submitted to a peer-reviewed or community-curated repository that, in turn, designates digital object identifiers for data sets. This process fulfills publication requirements for open-access FAIR (findable, accessible, interoperable, and reusable) data, makes data sets accessible for database updates, and gives credit to data generators for any future use.
Ideally, a platform will be created where experts from the research community can be incentivized to invest time to further quality check these standardized data sets uploaded to repositories and then add them to the SISAL research database. In turn, platforms (e.g., Linked Paleo Data, Neotoma, NCEI) containing multiple data sets holding speleothem, sediment, ice core, and other climate data sets can continue facilitating discussions to ensure standardization across proxies and archives.
The SISAL database and associated materials are freely accessible online. Further updates of the database will hinge on researchers volunteering and taking the lead, but at least these efforts will not be limited by the lack of a database infrastructure or an active global speleothem community. Research databases and a community-level mindset of making data accessible for future projects are an efficient approach to further our understanding Earth’s past and future climates.
Acknowledgments
We thank Andy Baker, Kira Rehfeld, Amy Frappier, and Yuval Burstyn for their input to this article. This study was undertaken by the SISAL (Speleothem Isotopes Synthesis and Analysis) working group of the Past Global Changes (PAGES) project, which in turn received support from the U.S. National Science Foundation, the Swiss Academy of Sciences, and the Chinese Academy of Sciences.
References
Ait Brahim, Y., et al. (2020), Exploiting the SISALv2 database for evaluating climate processes, PAGES Mag., 28(1), 27, https://doi.org/10.22498/pages.28.1.27.
Atsawawaranunt, K., et al. (2018), The SISAL database: A global resource to document oxygen and carbon isotope records from speleothems, Earth Syst. Sci. Data, 10(3), 1,687–1,713, https://doi.org/10.5194/essd-10-1687-2018.
Cauquoin, A., et al. (2019), Water isotopes-climate relationships for the mid-Holocene and preindustrial period simulated with an isotope-enabled version of MPI-ESM, Clim. Past, 15(6), 1,913–1,937, https://doi.org/10.5194/cp-15-1913-2019.
Comas-Bru, L., et al. (2017), From caves to climate: Creating the SISAL global speleothem database, PAGES Mag., 25(3), 156, https://doi.org/10.22498/pages.25.3.156.
Comas-Bru, L., et al. (2019), Evaluating model outputs using integrated global speleothem records of climate change since the last glacial, Clim. Past, 15(4), 1,557–1,579, https://doi.org/10.5194/cp-15-1557-2019.
Comas-Bru, L., et al. (2020), SISALv2: A comprehensive speleothem isotope database with multiple age-depth models, Earth Syst. Sci. Data, 12(4), 2,579–2,606, https://doi.org/10.5194/essd-12-2579-2020.
Goldscheider, N., et al. (2020), Global distribution of carbonate rocks and karst water resources, Hydrogeol. J., 28, 1,661–1,677, https://doi.org/10.1007/s10040-020-02139-5.
Khider, D., et al. (2019), PaCTS 1.0: A crowdsourced reporting standard for paleoclimate data, Paleoceanogr. Paleoclimatol., 34(10), 1,570–1,596, https://doi.org/10.1029/2019PA003632.
Author Information
Nikita Kaushal ([email protected]), Asian School of the Environment, Nanyang Technological University, Singapore; Laia Comas-Bru, School of Archaeology, Geography and Environmental Sciences, University of Reading, U.K.; Franziska A. Lechleitner, Department of Chemistry and Biochemistry and Oeschger Centre for Climate Change Research, University of Bern, Switzerland; and István Gabor Hatvani and Zoltán Kern, Institute for Geological and Geochemical Research, Research Centre for Astronomy and Earth Sciences, Budapest, Hungary
Citation:
Kaushal, N.,Comas-Bru, L.,Lechleitner, F. A.,Hatvani, I. G., and Kern, Z. (2021), Improving access to paleoclimate data, Eos, 102, https://doi.org/10.1029/2021EO155315. Published on 01 March 2021.
Text © 2021. The authors. CC BY-NC-ND 3.0
Except where otherwise noted, images are subject to copyright. Any reuse without express permission from the copyright owner is prohibited.